CS61B学习笔记(十五)-Rd12-哈希表
目前的问题
到目前为止,我们已经了解了一些数据结构,以便有效地搜索数据结构中是否存在项目。我们研究了二叉搜索树,然后使用 2-3 棵树使它们平衡。
然而,这些结构存在一些限制(是的,甚至是 2-3 棵树)
他们要求项目具有可比性。您如何决定新项目在 BST 中的位置?你必须回答“你比根小还是大”的问题?对于某些对象来说,这个问题可能没有意义。
它们给出的复杂度为
Θ(logN)。这个好吗?绝对地。但也许我们可以做得更好。
第一次尝试: DataIndexedIntegerSet
目前,我们只尝试改进上面的问题#2(将复杂性从 Θ(logN) 提高到 Θ(1) 。我们不会担心问题#1(可比性)事实上,我们只会考虑存储和搜索 int 。
这里有一个想法:让我们创建一个类型为 boolean 且大小为 20 亿的 ArrayList。让一切默认为假。
add(int x)方法只是将 ArrayList 中的x位置设置为 true。这需要 Θ(1)Θ(1) 时间。contains(int x)方法只是返回 ArrayList 中的x位置是true还是false。这也需要Θ(1)时间!
1 | public class DataIndexedIntegerSet { |

这种方法有哪些潜在问题?
- 极其浪费。如果我们假设
boolean需要 1 个字节来存储,则上面的每个new DataIndexedIntegerSet()需要2GB空间。此外,用户只能插入少量项目…… - 如果有人想插入
String我们该怎么办?
解决单词插入问题
我们的 DataIndexedIntegerSet 只允许使用整数,但现在我们想要将 String "cat" 插入其中。我们将可以插入字符串的数据结构称为 DataIntexedEnglishWordSet 这是一个疯狂的想法:让我们给每个字符串一个数字。也许“cat”可以是 1 ,“dog”可以是 2 ,“turtle”可以是 3 。
(这样做的方式是——如果有人想在我们的数据结构中添加一只“猫”,我们会“算出”“猫”的数字是 1,然后将 present[1] 设置为是 true 。如果有人想问我们“cat”是否在我们的数据结构中,我们会“找出”“cat”是 1,并检查 present[1] 是否为 true .)
但如果有人试图插入“potatocactus”这个词,我们就不知道该怎么办了。我们需要制定一个通用策略,以便给定一个字符串,我们可以找出它的数字表示形式。
策略 1:使用第一个字母。
一个简单的想法是仅使用任何给定字符串的第一个字符将其转换为其数字表示形式。所以“cat”->“c”-> 3。“Dog”->“d”-> 4。而且,“drum”->“d”-> 4。
如果有人想在我们的 DataIntexedEnglishWordSet 中插入“dog”和“drum”怎么办?所有的赌注都落空了,我们不知道该怎么做。
请注意,当两个不同的输入(“dog”和“drum”)映射到同一整数时,我们称之为碰撞。我们还不知道如何处理碰撞,所以让我们想办法避免它们。
策略 2:避免碰撞
我们知道英语小写字母中有26个独特的字符,我们可以先将其编号:a = 1, b = 2, …, z = 26,我们可以将单词每个字母进行加权。
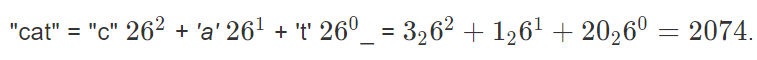
这种表示形式为每个包含小写字母的英语单词提供了一个唯一的整数,就像使用基数 10 为每个数字提供了唯一的表示形式一样。我们保证不会发生碰撞。
我们的数据结构 DataIndexedEnglishWordSet
1 | public class DataIndexedEnglishWordSet { |
使用辅助方法
1 | public static int letterNum(String s, int i) { |
目前进度
- 我们的方法仍然非常浪费内存。我们还没有解决这个问题!
- 只局限于整数和英语小写字母
- 比 Θ(logN) 更好。现在我们已经对整数和单个英语单词进行了此操作。
- 无法存储
2pac这样的字符串
在单个英文单词之外插入 String
有一种称为 ASCII 的字符格式,每个字符都有一个整数。在这里,我们看到最大值(即我们需要使用的基数/乘数)是 126。让我们这样做。与 DataIndexedEnglishWordSet 相同,但只是使用基础 126 。
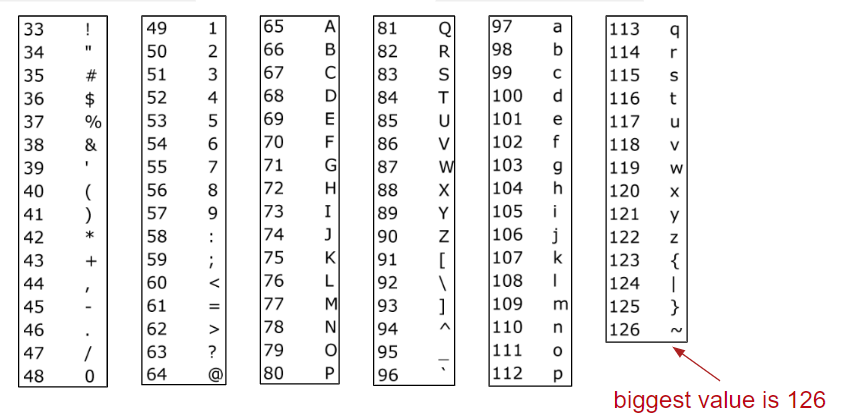
1 | public static int asciiToInt(String s) { |
添加对中文的支持怎么样?最大可能的表示形式是 40959,因此我们需要使用它作为基础。这是一个例子:
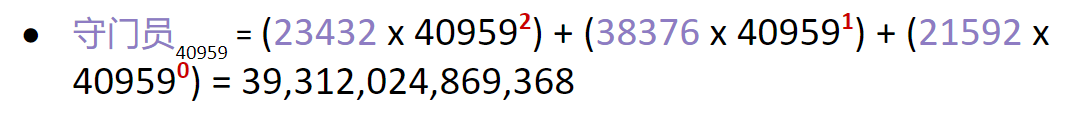
所以…为了存储一个 3 个字符的中文单词,我们需要一个大小大于 39 万亿(带 T)的数组!这已经失控了……所以让我们探讨一下我们能做什么。
处理整数溢出和哈希码
Java 中整数的最大可能值为 2,147,483,647。最小值为-2,147,483,648。
如果你尝试取最大值并加 1,你会得到最小值!
因此,即使只使用 ASCII 字符(记住,以 126 为基数),我们也会遇到问题。
对于omens126=28,196,917,171 .asciiToInt(omens) 返回 -1,867,853,901.
由于溢出, melt banana 和 subterresetrial anticosmetic 实际上根据 asciiToInt 具有相同的表示。因此,如果我们添加 melt banana 然后尝试询问 contains(subterrestrial anticosmetic) ,我们会得到 true 。
不可避免的事实。
从最小到最大可能的整数,Java 中总共有 4,294,967,296 个整数。然而,Java 中可以创建的对象总数远不止于此,因此冲突是不可避免的。抵抗是徒劳的。我们必须弄清楚如何正面处理碰撞,而不是试图解决它。
(如果您不相信在 Java 中可以创建超过 40 亿个对象,只需考虑一下:“一”、“二”、…、“五万亿”——每个都是一个唯一的字符串。 )
我们必须处理碰撞。
哈希码
在计算机科学中,获取一个对象并将其转换为某个整数称为“计算该对象的哈希码”。例如,“meltbanana”的哈希码是839099497。
哈希函数——来自 Wolfram MathWorld — Hash Function – from Wolfram MathWorld
我们研究了如何计算字符串的哈希码。对于其他对象,我们执行以下两件事之一:
- Java中的每个对象都有一个默认的
.hashcode()方法,我们可以使用它。 Java 通过计算Object在内存中的位置(计算机内存的每个部分都有一个地址!)来计算此值,并使用该内存地址执行类似于我们对Strings。该方法为每个 Java 对象提供唯一的哈希码。 - 有时,我们编写自己的
hashcode方法。例如,给定一个Dog,我们可以使用它的name、age和breed的组合来生成hashcode
哈希码的属性
哈希码具有三个必要的属性,这意味着哈希码必须具有以下属性才能有效:
- 它必须是一个整数
- 如果我们在一个对象上运行
.hashCode()两次,它应该返回相同的数字 - 被视为
.equal()的两个对象必须具有相同的哈希码。
然而,并非所有哈希码都是一样的。如果你希望你的哈希码被认为是一个好的哈希码,它应该:
- 均匀分配物品
请注意,此时,我们知道如何向数据结构添加任意对象,而不仅仅是字符串。
未决问题
- 空间:我们还没有弄清楚如何使用更少的空间。
- 处理碰撞:我们已经确定需要处理碰撞,但我们还没有真正处理它们。
处理碰撞
最重要的想法是稍微改变我们的数组,使其不只包含项目,而是包含项目的 LinkedList(或任何其他列表)。所以…
数组中的所有内容原本都是空的。
如果我们得到一个新项目,它的哈希码是 $h$:
- 如果索引 $h$ 目前没有任何内容,我们将为索引 $h$ 创建一个新的
LinkedList,将其放置在那里,然后将新项目添加到新创建的LinkedList - 如果索引 $h$ 处已经有一些东西,那么那里已经有一个
LinkedList。我们只需将新项目添加到LinkedList中即可。注意:我们的数据结构不允许有任何重复的项/键。因此,我们必须首先检查我们要插入的项是否已经在此 LinkedList 中。如果是的话,我们什么也不做!这也意味着我们将插入到链表的末尾,因为无论如何我们都需要检查所有元素。
具体工作流程
add项目获取项目的哈希码(即索引)。
如果索引没有项目,则创建新列表,并将项目放置在那里。
如果索引已经有一个列表,请检查列表以查看项目是否已在其中。如果没有,请将项目添加到列表中。
contains项目- 获取项目的哈希码(即索引)。
- 如果索引为空,则返回
false。 - 否则,检查列表中该索引处的所有项目,如果该项目存在,则返回
true。
运行时复杂性
由于我们需要通过哈希码(即索引)查看 LinkedList 中的所有项目。所以contains的复杂度是Θ(Q)
因为我们必须检查以确保该项目尚未位于链接列表中,所以add的复杂度是Θ(Q)
解决空间
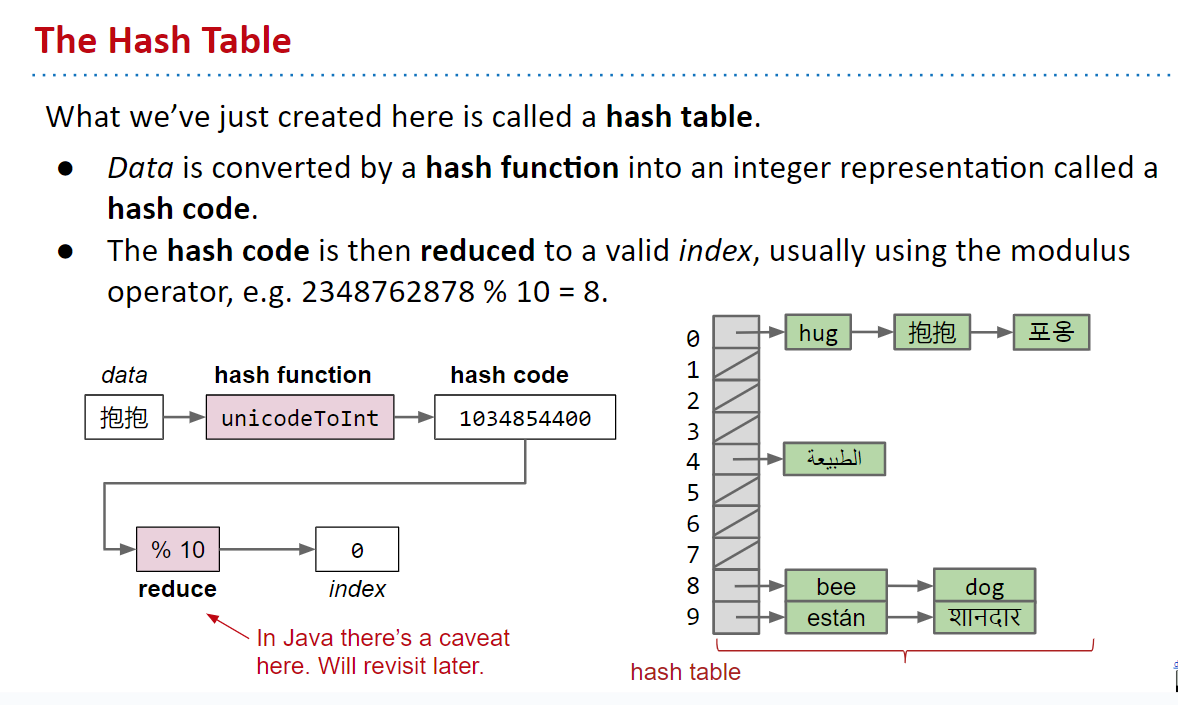
让我们创建一个大小为 100 的 ArrayList。我们不要更改 hashcode 函数的行为方式(让它返回一个疯狂的大整数。)但是在获得 hashcode 后,我们将对其取模 100 以获得我们想要的 0…990…99 范围内的索引。
目前进度
- 空间:已解决。
- 处理碰撞:完成!
- 运行时复杂度?我们之前在 Θ(�)Θ(Q) 处为
add和contains丢失了一些,然后在解决空间部分,我们意识到我们丢失了更多,因为我们的 LinkedList 可能会更大(因此Q会更大。)
我们最终的数据结构: HashTable
我们现在创建的称为 HashTable 。
- 输入由哈希函数 (
hashcode) 转换为整数。然后,使用模运算符将它们转换为有效索引。然后,它们被添加到该索引处(使用 LinkedList 处理冲突)。 contains通过找出有效索引并在相应的 LinkedList 中查找该项目以类似的方式工作。
处理运行时间
唯一需要解决的问题是运行时间问题。如果我们有 100 个项目,并且 ArrayList 的大小为 5,那么
- 在最好的情况下,所有项目都会均匀地发送到不同的索引。也就是说,我们有 5 个 linkedList,每个 linkedList 包含 20 个项目。
- 在最坏的情况下,所有项目都会发送到同一个索引!也就是说,我们只有 1 个 LinkedList,但它包含全部 100 个项目。
有两种方法可以尝试解决此问题:
- 动态增长我们的哈希表。
- 改进我们的哈希码
动态增长哈希表
假设我们有 M 个桶(索引)和 N 个项。我们说我们的装载因子是 N/M。
(注意,装载因子等同于我们上面的最佳情况运行时间。)
所以…我们有动机保持我们的装载因子低(毕竟,这是我们可能实现的最佳运行时间!)。
注意,如果我们保持 M(桶的数量)固定,而 N 不断增加,装载因子会不断增加。
策略?每隔一段时间,将 M 加倍。我们这样做的方式如下:
- 创建一个具有 2M 个桶的新哈希表。
- 遍历旧哈希表中的所有项,逐个将它们添加到这个新哈希表中。
- 我们需要再次逐个添加元素,因为由于数组的大小变化,模数也会变化,因此该项可能属于新哈希表中的不同桶而不是旧哈希表中的桶。
我们通过设置装载因子阈值来执行此操作。一旦装载因子大于此阈值,我们就会调整大小。
看一下下面的例子。”helmet” 的哈希码是 13。在第一个哈希表中,它被发送到桶 13%4=1。在第二个哈希表中,它被发送到桶 13%8=5。请注意,调整哈希表的大小也有助于打乱哈希表中的项!
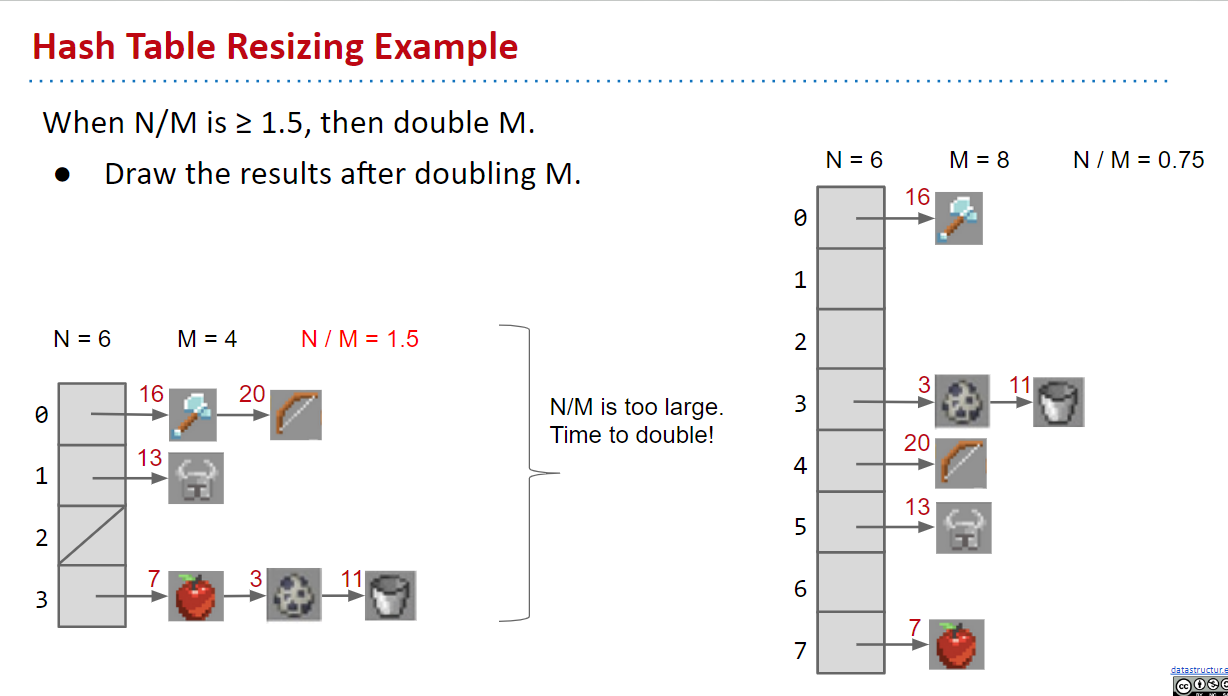
在这一点上,假设项目均匀分布,所有列表大约都会是 N/M 个项目长,导致 Θ(N/M) 运行时间。请记住,N/M 只允许在一个常数装载因子阈值下,因此, Θ(N/M)=Θ(1)。
还要注意,调整大小需要 Θ(N) 时间。为什么?因为我们需要将 N 个项目添加到哈希表中,并且每次添加都需要 Θ(1) 时间。
一个小细节:当进行调整大小时,我们实际上不需要检查项是否已经存在于链表中(因为我们知道没有重复项),因此我们可以确保将每个项都在 Θ(1) 时间内添加到链表的前面。(回想一下,通常情况下,我们必须搜索链表以确保项不在那里…但是当调整大小时,我们可以跳过该步骤。)
当然,我们需要重新审视假设项目均匀分布的假设。如果项目不均匀分布,我们的运行时间将是 Θ(N),因为可能会存在一个大小为 N 的单个链表。
假设物品均匀分布?
如果我们有好的哈希码(即为不同项目提供相当随机的值的哈希码),项目将均匀分布。)一般来说,这样做是……嗯……很难。
一些通用的好的经验法则:
- 使用与我们之前开发的策略类似的“基本”策略。
- 使用一个小质数的“基数”。
- Base 126 实际上并不是很好,因为使用 Base 126 意味着以相同的最后 32 个字符结尾的任何字符串都具有相同的哈希码。
- 发生这种情况是因为溢出。
- 使用素数有助于避免溢出问题(即由于溢出而导致的冲突)。
- 为什么是小素数?因为它更容易计算。
哈希表的普及
哈希表是集合和映射的最流行实现。
- 在实践中性能出色。
- 不需要项可比较。
- 实现通常相对简单。
- Python 字典实际上就是哈希表。
在 Java 中,它们以 java.util.HashMap 和 java.util.HashSet 实现
- HashMap 如何知道如何计算每个对象的哈希码?
- 好消息是:不是“implements Hashable”。
- 相反,在 Java 中,所有对象必须实现一个 .hashCode() 方法。
代码实现
代码介绍在Lab8中
起始代码在skeleton-sp21/lab8 at master · Berkeley-CS61B/skeleton-sp21 (github.com)仓库中
具体实现在博客(项目笔记五)[https://www.bailog.top/2024/03/04/JAVA-CS61B-项目笔记-5-CS61B项目笔记-Lab8-哈希表/]



