CS61B项目笔记(七)-proj2
项目2:Gitlet | CS 61B 2021 年春季 — Project 2: Gitlet | CS 61B Spring 2021 (datastructur.es)要求介绍
翻译
项目 2: Gitlet
关于此规范的说明
此规范相当长。前半部分详细描述了您将支持的每个命令,另一半是测试详细信息和一些建议。为了帮助您理解,我们准备了许多高质量的视频,描述了规范的各个部分,并提供建议。所有视频都链接在本规范的相关位置,但我们也将在此列出它们以方便您查看。请注意:这些视频中的一些是在 2020 年春季创建的,当时 Gitlet 是项目 3,Capers 是 Lab 12,并且一些视频简要提及了 Hilfinger 教授的 CS 61B 设置(包括名为 shared 的远程,名为 repo 的存储库等)。请忽略这些内容,因为它们对本学期的您没有任何有用的信息。任务的实际内容没有改变。
- Git 介绍 - 第 1 部分
- Git 介绍 - 第 2 部分
- 直播讲座 12
- Gitlet 介绍播放列表
- 合并概述和示例
- 分支概述和示例
- 测试
- 设计持久性(书面笔记)
- 2021 年春季办公时间演示:
随着更多资源的创建,我们将在此处添加它们,因此请经常刷新!
Gitlet 概述
警告:确保您在进行此项目之前已完成实验 6: Canine Capers。实验 6 旨在介绍此项目,并将非常有助于启动和确保您已做好准备。您还应该观看直播讲座 12: Gitlet,该讲座介绍了此项目的许多有用想法。
在此项目中,您将实现一个版本控制系统,模仿了流行系统 Git 的一些基本功能。但我们的系统更小更简单,因此我们将其命名为 Gitlet。
版本控制系统本质上是一种相关文件集的备份系统。Gitlet 支持的主要功能包括:
- 保存整个文件目录的内容。在 Gitlet 中,这称为提交,保存的内容本身称为提交。
- 恢复一个或多个文件或整个提交的版本。在 Gitlet 中,这称为检出这些文件或该提交。
- 查看备份历史。在 Gitlet 中,您可以在称为日志的内容中查看此历史记录。
- 维护相关的提交序列,称为分支。
- 将在一个分支中进行的更改合并到另一个分支中。
版本控制系统的目的是帮助您创建复杂(甚至不那么复杂)的项目,或者与他人共同在项目上合作。您会定期保存项目的版本。如果以后某个时刻意外地搞乱了您的代码,那么您可以将源代码恢复到之前提交的版本(而不会丢失此后所做的任何更改)。如果您的合作者做了一些更改并体现在提交中,则可以将这些更改合并到自己的版本中。
在 Gitlet 中,您不仅可以一次提交单个文件。相反,您可以同时提交一组相关文件。我们喜欢将每个提交视为您项目在某个时间点的快照。但为简单起见,本文档剩余部分中的许多示例涉及每次更改一个文件。只需记住,您可以在每次提交中更改多个文件。
在此项目中,我们将可视化随时间进行的提交。假设我们有一个项目,只包含文件 wug.txt,我们向其中添加了一些文本并提交了它。然后我们修改了文件并提交了这些
更改。然后我们再次修改了文件,并再次提交了更改。现在我们已保存了这个文件的三个版本,每个版本都晚于之前的版本。我们可以像这样可视化这些提交:

在这里,我们绘制了一个箭头,指示每个提交包含对之前提交的某种引用。我们将前面的提交称为父提交——这在后面会很重要。但是现在,这个图看起来熟悉吗?没错;这是一个链表!
Gitlet 的重要思想是,我们可以在这样的列表中可视化我们文件的不同版本的历史。然后,我们可以很容易地恢复文件的旧版本。您可以想象制作一个命令:“Gitlet,请恢复到提交#2时的文件状态”,它会转到链表中的第二个节点,并恢复在那里找到的文件的副本,同时删除第一个节点中的任何文件,但不删除第二个节点中不存在的文件。
如果我们告诉 Gitlet 恢复到旧提交,那么链表的前面将不再反映文件的当前状态,这可能有点误导。为了解决这个问题,我们引入了一个称为头指针(也称为 HEAD 指针)的东西。头指针跟踪我们当前所在的链表中的位置。通常,当我们进行提交时,头指针将保留在链表的前端,表示最新的提交反映了文件的当前状态:
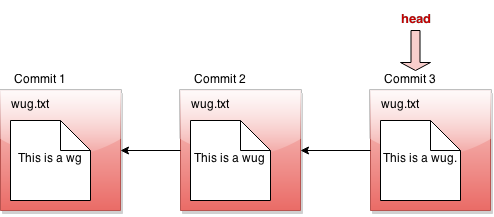
然而,假设我们恢复到提交#2时的文件状态(严格来说,这是 重置 命令,您稍后会看到)。我们将头指针移回以显示此:
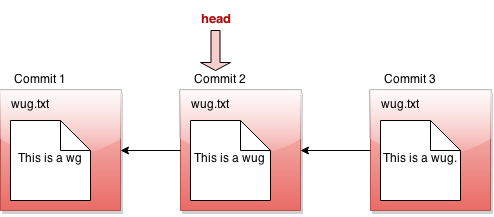
这里我们说我们处于分离的头状态,您可能之前遇到过这个。这就是它的含义!
编辑 3/5:请注意,在 Gitlet 中,由于没有 checkout 命令会将 HEAD 指针移动到特定提交,因此不可能处于分离 HEAD 状态。reset 命令会执行此操作,尽管它也会移动分支指针。因此,在 Gitlet 中,您永远不会处于分离的 HEAD 状态。
好了,现在,如果这就是 Gitlet 所能做的一切,那么它将是一个相当简单的系统。但是 Gitlet 还有一个更聪明的功能:它不仅维护文件的旧版本和新版本,还可以维护不同的版本。想象一下,您正在编写一个项目,您对如何进行以下两种想法:让我们称其中一种为计划 A,另一种为计划 B。Gitlet 允许您保存这两个版本,并随时在它们之间切换。这可能看起来像这样:
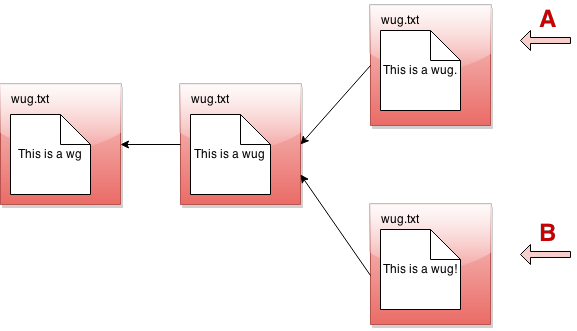
它不再是一个链表。它更像是一棵树。我们将这个东西称为提交树。保持这个隐喻,各个单独的版本称为树的分支。您可以单独开发每个版本:
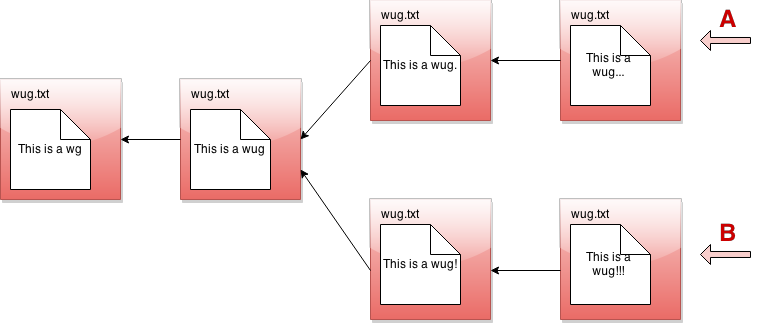
树中有两个指针,表示每个分支的最远点。在任何给定时间,只有一个是当前活动指针,这就是所谓的头指针。头指针是当前分支前端的指针。
这就是我们对 Gitlet 系统的简要概述!如果您还不完全了解,请不要担心;上面的部分只是为了给您一个高层次的图片,说明它的目的是做什么。接下来的详细规范将在此部分后面。
但是在这里最后一句话:提交树是不可变的:一旦创建了提交节点,就无法销毁(或者根本无法更改)。我们只能向提交树添加新内容,而不能修改现有内容。这是 Gitlet 的一个重要特性!Gitlet 的一个目标是允许我们保存东西,以免意外删除它们。
内部结构
真正的 Git 区分了几种不同的对象。就我们的目的而言,重要的对象包括
- blobs:文件的保存内容。由于 Gitlet 保存文件的多个版本,因此单个文件可能对应于多个 blobs:每个 blobs 在不同提交中被跟踪。
- trees:将名称映射到 blobs 和其他树(子目录)的目录结构。
- commits:包含日志消息、其他元数据(提交日期、作者等)、对树的引用以及对父提交的引用的组合。存储库还维护从分支头到对提交的引用的映射,以便某些重要的提交具有符号名称。
Gitlet 进一步简化了 Git,具体包括
- 将树结构合并到提交中,而不处理子目录(因此每个存储库将有一个“平面”目录,其中包含普通文件)。
- 限制我们将合并与两个
父亲联系起来(在真实的 Git 中,可以有任意数量的父亲。)
- 我们的元数据仅包含时间戳和日志消息。因此,提交将由日志消息、时间戳、文件名到 blob 引用的映射、父引用以及(对于合并)第二父引用组成。
我们的每个对象——我们的每个 blob 和每个提交,在我们的情况下——都有一个唯一的整数 id,它作为对该对象的引用。Git 的一个有趣的特性是这些 id 是全局的:与典型的 Java 实现不同,具有完全相同内容的两个对象在所有系统上(即我的计算机、您的计算机和任何其他人的计算机)上都具有相同的 id(即两个对象在不同计算机上具有相同的 id)。在 blobs 的情况下,“相同内容”意味着相同的文件内容。在提交的情况下,这意味着相同的元数据、名称到引用的映射和父引用。存储库中的对象因此被称为内容寻址。
Git 和 Gitlet 通过使用一个名为 SHA-1(Secure Hash 1)的加密散列函数实现了这一点,该函数可以从任意字节序列产生一个 160 位整数哈希。加密哈希函数的特性是极难找到具有相同哈希值的两个不同的字节流(或者在仅给出其哈希值的情况下找到任何字节流),因此从本质上讲,我们可以假设任何两个具有不同内容的对象具有相同的 SHA-1 哈希值的概率是 2-160 或约为 10-48。基本上,我们简单地忽略了哈希碰撞的可能性,因此原则上系统具有一个基本的缺陷,但在实践中从未发生!
幸运的是,有用于计算 SHA-1 值的库类,因此您不必处理实际算法。您需要做的一切就是确保正确地标记所有对象。特别是,这包括
- 在计算提交的哈希值时包括所有元数据和引用。
- 在 blobs 和提交的哈希之间某种区分。通过
.gitlet目录内部的一种精心考虑的目录结构是一个很好的方法。另一种方法是为每个对象添加一个额外的字,该字对于 blobs 和提交具有一个值。
顺便说一下,SHA-1 哈希值,表示为 40 字符的十六进制字符串,是将数据存储在 .gitlet 目录中的方便文件名(稍后会详细介绍)。它还提供了一种比较两个文件(blobs)以查看它们是否具有相同内容的方便方法:如果它们的 SHA-1 相同,则我们简单地假设这些文件是相同的。
对于远程(例如我们整个学期都在使用的 skeleton),我们将只是使用其他 Gitlet 存储库。推送意味着将远程存储库尚未拥有的所有提交和 blobs 复制到远程存储库,并重置分支引用。拉取也是如此,但方向相反。在本项目中,远程是额外的学分,不是必须的。
读取和写入内部对象到文件其实相当容易,这要归功于Java的序列化功能。接口java.io.Serializable没有方法,但如果一个类实现了它,那么Java运行时将自动提供一种将对象转换为字节流的方法,然后您可以使用I/O类java.io.ObjectOutputStream将其写入文件,并使用java.io.ObjectInputStream读取(反序列化)。术语“序列化”指的是将某种任意结构(数组、树、图等)转换为字节序列的过程。你应该在实验6中已经见过并练习了序列化。你将在这里使用一个非常类似的方法,因此在持久性和序列化方面请使用你的lab6作为参考。
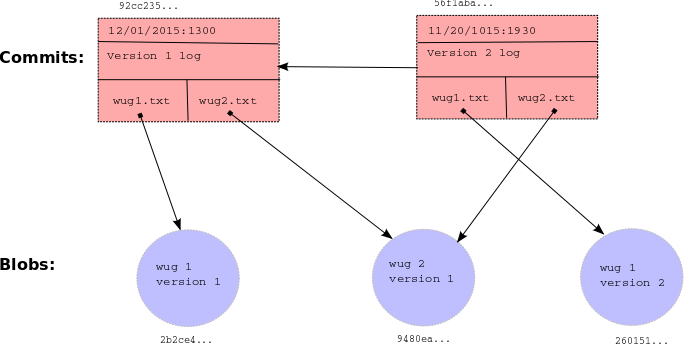
下面是本节讨论的结构的摘要示例。正如你所看到的,每个提交(矩形)指向一些Blob(圆圈),其中包含文件内容。提交包含文件名和对这些Blob的引用,以及父链接。这些引用,表示为箭头,在.gitlet目录中使用它们的SHA-1哈希值表示(在提交上方和Blob下方的小十六进制数值)。更新的提交包含wug1.txt的更新版本,但与旧提交相同版本的wug2.txt。你的提交类将以某种方式存储此图表显示的所有信息:仔细选择内部数据结构将使实现变得更容易或更难,因此你应该花时间计划和考虑最佳存储方式。
行为的详细规范
总体规范
我们唯一给你的结构要求是你必须有一个名为gitlet.Main的类,并且它必须有一个主方法。
我们还为您提供了一些用于执行许多与文件系统相关的任务的实用方法,以便您可以集中精力于项目的逻辑,而不是处理操作系统的特殊性。
我们还添加了两个建议的类:Commit和Repository以帮助您入门。当然,您可以编写其他Java类来支持您的项目,或者如果您愿意,可以删除我们建议的类。但是不要使用任何外部代码(除了JUnit),也不要使用除Java之外的任何编程语言。您可以使用您希望使用的所有Java标准库,以及我们提供的实用程序。
你不应该在Main类中做所有事情。您的Main类应该主要调用Repository类中的辅助方法。查看实验6的CapersRepository和Main类,以了解我们建议的结构示例。
这份规范的大部分内容将描述当Gitlet.java的主方法收到各种gitlet命令作为命令行参数时必须如何反应。但在我们逐条分解命令之前,这里有一些整体指南整个项目都应该满足的:
- 为了使Gitlet正常工作,它将需要一个存储旧文件副本和其他元数据的地方。所有这些东西必须存储在名为
.gitlet的目录中,就像实际的git系统中的信息存储在名为.git的目录中一样(以.开头的文件是隐藏文件。您无法在大多数操作系统上默认看到它们。在Unix上,命令ls -a将显示它们。)如果在一个位置有一个.gitlet目录,那么就认为Gitlet系统在那里“初始化”了。大多数Gitlet命令(除了init命令)只需要在初始化了Gitlet系统的目录中使用时才能工作——也就是说,在包含.gitlet目录的目录中。不在您的.gitlet目录中的文件(它们是您使用和编辑的仓库中的文件的副本,以及您计划添加到仓库中的文件)被称为您工作目录中的文件。 - 大多数命令有运行时或内存使用要求。您必须遵循这些要求。其中一些运行时描述为常量“相对于任何重要度量”。重要度量包括:文件的数量或大小的任何度量,提交数量的任何度量。您可以忽略序列化或反序列化所需的时间,但有一个例外,即您的序列化时间不能以任何方式依赖已添加、提交等文件的总大小(什么是序列化?如果您不知道,请回顾实验6!)。您还可以假设从哈希表中获取是常量时间。
- 一些命令具有带有指定错误消息的失败情况。这些错误消息的确切格式稍后在规范中指定。所有错误消息都以句号结尾;由于我们的自动分级是文字性的,请务必包括它。如果您的程序曾遇到其中一种失败情况,则必须打印错误消息并不更改任何其他内容。您不需要处理除列出为失败情况之外的任何其他错误情况。
- 有一些失败情况您需要处理,这些失败情况不适用于特定命令。这里它们是:
- 如果用户没有输入任何参数,请打印消息
Please enter a command.并退出。 - 如果用户输入一个不存在的命令,请打印消息
No command with that name exists.并退出。 - 如果用户输入具有错误数量或格式的操作数的命令,请打印消息
Incorrect operands.并退出。 - 如果用户输入一个需要在初始化的 Gitlet 工作目录中(即包含
.gitlet子目录的目录)的命令,但不在这样的目录中,则打印消息Not in an initialized Gitlet directory. - 一些命令与真实的 Git 有所不同。规范没有详尽列出与 Git 的 所有 不同之处,但它确实列出了一些较大或潜在混淆和误导的差异。
- 不要 输出除了规范中所说的之外的任何内容。我们的自动评分测试中可能会有一些打印不必要信息的测试会出错。
- 若要立即退出程序,您可以调用
System.exit(0)。例如,如果在辅助函数中发生错误,并且您希望 gitlet 立即终止,则应调用此函数。注意:您应该始终为System.exit(0)命令提供参数 0。在 61C 中,您将了解参数(称为错误代码)的含义。 - 规范将一些命令分类为“危险”。危险命令是那些可能覆盖文件(不仅仅是元数据)的命令 - 例如,如果用户告诉 Gitlet 将文件恢复到旧版本,Gitlet 可能会覆盖文件的当前版本。请注意。因此,在测试这些命令之前,请戴上头盔 :)
- 如果用户没有输入任何参数,请打印消息
命令
我们现在将详细介绍您必须支持的每个命令。请记住,优秀的程序员始终关心他们的数据结构:当您阅读这些命令时,您应该首先考虑如何存储您的数据以便轻松支持这些命令,并其次考虑是否有机会重用您已经实现的命令(提示:在项目2的后续部分中,您已经在项目2的较早部分中编写的代码可以得到充分的重用机会)。我们在一些我们发现有用的方法中列出了讲座,但您不必使用这些讲座中的概念。一些更加复杂的命令上有概念性的测验,您应该使用它们来检查您的理解。这些测验不计入成绩,它们只是帮助您在尝试实现命令之前检查您的理解。
init
- 用法:
java gitlet.Main init - 描述:在当前目录中创建一个新的 Gitlet 版本控制系统。该系统将自动开始一个提交:一个不包含文件且具有提交消息
initial commit(就是这样,没有标点符号)。它将有一个单一分支:master,最初指向此初始提交,并且master将是当前分支。此初始提交的时间戳将为 00:00:00 UTC,Thursday, 1 January 1970,以您选择的日期格式(这被称为“Unix 纪元”,内部由时间 0 表示)。由于由 Gitlet 创建的所有存储库中的初始提交都具有完全相同的内容,因此所有存储库将自动共享此提交(它们将具有相同的 UID),并且所有存储库中的所有提交都将追溯到它。 - 运行时间:相对于任何重要指标,应该是恒定的。
- 失败情况:如果当前目录中已经存在 Gitlet 版本控制系统,则应中止。不应使用新系统覆盖现有系统。应打印错误消息
A Gitlet version-control system already exists in the current directory.。 - 危险吗:否
- 我们的代码行数:~15
add
- 用法:
java gitlet.Main add [文件名] - 描述:将文件的当前副本添加到暂存区(参见
commit命令的描述)。因此,添加文件也称为为添加而暂存文件。将已经暂存的文件暂存会使用新内容覆盖暂存区中的先前条目。暂存区应该位于.gitlet的某个地方。如果文件的当前工作版本与当前提交中的版本相同,则不要将其暂存以添加,并且如果已经存在(当文件更改、添加,然后更改回其原始版本时可能会发生)的情况下,从暂存区删除它。文件将不再被暂存以删除(请参见gitlet rm),如果在命令时处于该状态。 - 运行时间:在最坏的情况下,应相对于要添加的文件的大小和 lgNlg� 运行,其中 N� 是提交中的文件数量。
- 失败情况:如果文件不存在,则打印错误消息
File does not exist.并且退出而不更改任何内容。 - 危险吗:否
- 我们的代码行数:~20
- 与真实 git 的区别:在真实的 git 中,可以一次添加多个文件。在 gitlet 中,一次只能添加一个文件。
- 建议的讲座:讲座16(集合、映射、ADTs)、讲座19(哈希)
commit
用法:
java gitlet.Main commit [消息]描述: 在当前提交和暂存区保存已跟踪文件的快照,以便稍后可以恢复,创建一个新的提交。该提交被称为跟踪保存的文件。默认情况下,每个提交的文件快照将与其父提交的文件快照完全相同;它将保留文件的版本完全不变,不会更新它们。提交仅会更新在提交时已标记为要添加的文件的内容,在这种情况下,提交现在将包含已标记为要添加的文件的版本,而不是从其父提交中获取的版本。提交将保存并开始跟踪任何已标记为要添加但父提交未跟踪的文件。最后,由于被
rm命令(下面)标记为要删除,当前提交中跟踪的文件可能会在新提交中被取消跟踪。要点总结:默认情况下,提交的文件内容与其父提交相同。标记为要添加和删除的文件是提交的更新内容。当然,日期(以及可能是消息)也与父提交不同。
关于提交的一些附加说明:
- 提交区在提交后被清除。
- 提交命令永远不会在工作目录中添加、更改或删除文件(除了
.gitlet目录中的文件)。rm命令将删除这些文件,并将它们标记为要删除,以便在commit后它们将不再被跟踪。 - 在添加或删除之后对文件进行的任何更改都将被
commit命令忽略,它只修改.gitlet目录的内容。例如,如果您使用Unix的rm命令(而不是Gitlet的同名命令)删除一个已跟踪的文件,那么它对下一个提交没有影响,下一个提交仍将包含(现在已删除的)文件版本。 - 提交命令后,新提交将作为提交树中的新节点添加。
- 刚刚进行的提交将成为“当前提交”,并且头指针现在指向它。先前的头提交是此提交的父提交。
- 每个提交应包含其制作时间和日期。
- 每个提交都有一个与之关联的日志消息,描述提交中文件的更改。这是由用户指定的。整个消息应仅占用传递给
main的args数组中的一个条目。要包含多个单词的消息,您必须将其用引号括起来。 - 每个提交由其SHA-1 id标识,该id必须包括其文件(blob)引用、父引用、日志消息和提交时间。
运行时间: 运行时间应与提交数量的任何度量相关的常量。运行时必须不会比跟踪的文件总大小的线性差。此外,此命令具有内存要求:提交必须将
.gitlet目录的大小增加的量不得超过提交时暂存要添加的文件的总大小,不包括附加元数据。这意味着不要存储提交从其父项接收的文件版本的冗余副本(提示:请记住blob是内容可寻址的,并利用SHA1优势)。您可以保存完整的附加文件副本;不要担心仅保存差异或类似的事情。失败情况: 如果没有文件被暂存,则中止。打印消息
No changes added to the commit.。每个提交必须有一个非空消息。如果没有,则打印错误消息Please enter a commit message.。对于已跟踪文件在工作目录中缺失或更改的情况不算是失败。完全忽略.gitlet目录外的所有内容。危险性: 没有
与真实Git的不同之处: 在真实的Git中,提交可能有多个父提交(由于合并)并且还具有更多元数据。
我们的代码行数: ~35
建议的讲座: 讲座19(集合、映射、ADTs)、讲座19(哈希)
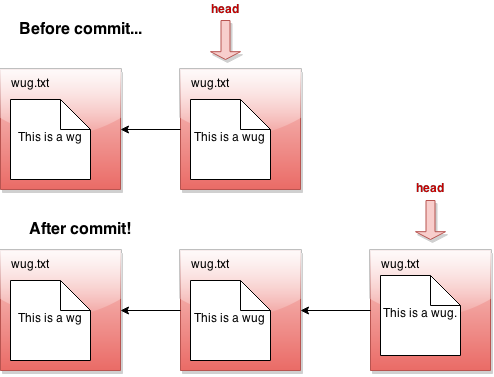
这是提交之前和之后的图片:
rm
- 用法:
java gitlet.Main rm [文件名] - 描述: 如果文件当前已暂存以添加,则取消暂存该文件。如果文件在当前提交中被跟踪,则将其标记为删除,并从工作目录中删除该文件(除非用户已经这样做,否则不要删除它)。
- 运行时间: 相对于任何重要度量的常量时间运行。
- 失败情况: 如果文件既没有被暂存也没有被当前提交跟踪,则打印错误消息
No reason to remove the file.。 - 危险性: 是的(尽管如果使用我们的实用方法,您只会损害您的存储库文件,而不是您目录中的所有其他文件。)
- 我们的代码行数: ~20
log
- 用法:
java gitlet.Main log - 描述: 从当前头提交开始,沿着提交树向后显示每个提交的信息,直到初始提交,跟随第一个父提交链接,忽略合并提交中找到的任何第二父提交(在常规Git中,这就是使用
git log --first-parent得到的)。这组提交节点称为提交的历史记录。对于历史记录中的每个节点,应显示的信息是提交ID、提交时间和提交消息。以下是应遵循的确切格式示例:
1 | === |
每个提交之前都有一个===,并且在其后有一个空行。与真实Git一样,每个条目显示提交对象的唯一SHA-1 ID。提交中显示的时间戳反映当前时区,而不是UTC;因此,初始提交的时间戳不是Thursday, January 1st, 1970, 00:00:00,而是相应的太平洋标准时间。您所在的时区可能因您的居住地而异,这没关系。
将最新的提交显示在顶部。顺便说一下,您会发现Java类java.util.Date和java.util.Formatter对于获取和格式化时间非常有用。查看它们,而不是尝试手动构造它们!
当然,SHA1标识符将是不同的,因此不要担心这些。我们的测试将确保您有一些“看起来像”SHA1标识符(有关测试部分的更多信息,请参见下文)。
对于合并提交(具有两个父提交),请在第一个父提交的下方添加一行,如下所示:
1 | === |
“Merge:”后面的两个十六进制数字由第一个和第二个父提交的提交ID的前七位数字组成,顺序如上所述。第一个父提交是合并时所在的分支;第二个是合并进来的分支。这与常规Git相同。
- 运行时间: 应与头部历史中节点数量的线性有关。
- 失败情况: 无
- 危险性: 否
- 我们的代码行数: ~20
这是特定提交的历史记录图片。如果当前分支的头指针恰好指向该提交,日志将打印有关圈中提交的信息:
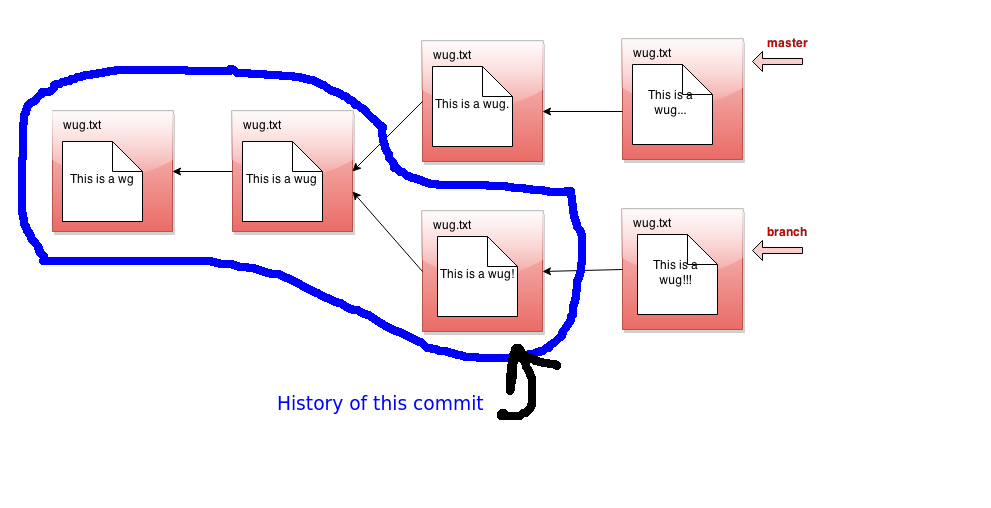
该历史记录忽略了其他分支和未来。既然我们已经介绍了历史记录的概念,让我们进一步完善我们之前关于提交树是不可变的说法。它的不可变性确切地体现在具有特定ID的提交的历史记录可能永远不会改变。如果您将提交树视为不可变的历史记录集合,那么我们实际上是在说每个历史记录都是不可变的。
global-log
- 用法:
java gitlet.Main global-log - 描述: 类似于日志,但显示有关已经进行的所有提交的信息。提交的顺序并不重要。提示:在
gitlet.Utils中有一个有用的方法,可以帮助您遍历目录中的文件。 - 运行时间: 相对于已经进行的提交数量的线性时间。
- 失败情况: 无
- 危险性: 否
- 我们的代码行数: ~10
find
- 用法:
java gitlet.Main find [提交消息] - 描述: 打印出具有给定提交消息的所有提交的ID,每行一个。如果有多个这样的提交,它会将ID分别打印在不同的行上。提交消息是一个单独的操作数;要指示多个单词的消息,请将操作数放在引号中,如下所示的
commit命令。提示:此命令的提示与global-log的提示相同。 - 运行时间: 相对于提交数量的线性时间。
- 失败情况: 如果不存在这样的提交,则打印错误消息
Found no commit with that message.。 - 危险性: 否
- 与真实git的不同: 在真实的git中不存在。可以通过搜索日志的输出来达到类似的效果。
- 我们的代码行数: ~15
status
用法:
java gitlet.Main status描述: 显示当前存在的分支,并用
*标记当前分支。还显示哪些文件已经被标记为添加或删除。它应该遵循的确切格式示例如下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18=== 分支 ===
*master
other-branch
=== 暂存的文件 ===
wug.txt
wug2.txt
=== 已删除的文件 ===
goodbye.txt
=== 未暂存的修改 ===
junk.txt (deleted)
wug3.txt (modified)
=== 未跟踪的文件 ===
random.stuff
最后两个部分(未暂存的修改和未跟踪的文件)是额外加分项,价值32分。可以将它们留空(只保留标题)。
每个部分之间有一个空行,并且整个状态以一个空行结束。条目应按字典顺序列出,使用Java字符串比较顺序(星号不计)。如果工作目录中的文件是“修改但未暂存”,则为以下情况之一:
- 在当前提交中跟踪,在工作目录中已更改,但未暂存;或
- 已标记为添加,但内容与工作目录中的内容不同;或
- 已标记为添加,但在工作目录中已删除;或
- 未标记为删除,但在当前提交中已跟踪并已从工作目录中删除。
最后一类(“未跟踪的文件”)是指存在于工作目录中但既未标记为添加也未跟踪的文件。这包括已标记为删除但在Gitlet不知情的情况下重新创建的文件。忽略可能已引入的任何子目录,因为Gitlet不处理它们。
运行时间: 确保这仅取决于工作目录中的数据量加上已标记为添加或删除的文件的数量加上分支的数量。
失败情况: 无
危险性: 否
我们的代码行数: ~45
checkout
检出是一种通用命令,可以根据其参数执行几种不同的操作。下面有3种可能的用法。在每个部分下面,您会看到3个编号的点。每个对应于相应的检出用法。
- 用法:
java gitlet.Main checkout -- [文件名]java gitlet.Main checkout [提交ID] -- [文件名]java gitlet.Main checkout [分支名]
- 描述:
- 获取文件在当前分支的最新提交中的版本,并将其放入工作目录中,如果已经存在同名文件,则覆盖它。新版本的文件不会被暂存。
- 获取文件在具有给定ID的提交中的版本,并将其放入工作目录中,如果已经存在同名文件,则覆盖它。新版本的文件不会被暂存。
- 获取给定分支头部的提交中的所有文件,并将它们放入工作目录中,如果已经存在同名文件,则覆盖它们。此外,在执行此命令结束时,给定分支将被视为当前分支(HEAD)。任何在当前分支中被跟踪但在检出分支中不存在的文件将被删除。暂存区将被清空,除非检出的分支是当前分支(参见失败情况下面)。
- 运行时间:
- 相对于正在检出的文件的大小,应该是线性的。
- 相对于提交快照中文件的总大小,应该是线性的。对于涉及提交数量的任何度量,应该是常数。对于分支数量的任何度量,应该是常数。
- 失败情况:
- 如果文件在上一个提交中不存在,则中止操作,并打印错误消息
File does not exist in that commit.不要更改当前工作目录。 - 如果不存在具有给定ID的提交,则打印
No commit with that id exists.。否则,如果文件在给定提交中不存在,则打印与失败情况1相同的消息。不要更改当前工作目录。 - 如果不存在具有该名称的分支,则打印
No such branch exists.如果该分支是当前分支,则打印No need to checkout the current branch.如果当前分支中有一个工作文件在检出时将被覆盖,则打印There is an untracked file in the way; delete it, or add and commit it first.并退出;在执行任何其他操作之前执行此检查。不要更改当前工作目录。
- 如果文件在上一个提交中不存在,则中止操作,并打印错误消息
- 与真实git的不同:真实的git不会清除暂存区,并将检出的文件暂存。此外,它不会执行可能覆盖或撤消您已暂存的更改(添加或删除)的检出操作。
一个[提交ID]就像前面描述的,是一个十六进制数。真实Git的一个方便的特性是,可以使用唯一前缀来缩写提交。例如,可以将
1 | a0da1ea5a15ab613bf9961fd86f010cf74c7ee48 |
缩写为
1 | a0da1e |
在(可能)没有其他以相同六个数字开头的SHA-1标识符的对象存在的情况下。您应该安排相同的事情发生在包含少于40个字符的提交ID中。不幸的是,使用缩短的ID可能会导致查找对象的速度变慢,如果实现得不好(使查找文件的时间与对象数量成线性关系),因此我们不会担心使用缩短的ID的命令的时间。但我们建议您在.git目录(特别是.git/objects)中查看它是如何加速搜索的。您可能会发现一个熟悉的数据结构实现在文件系统中而不是指针。
只有版本3(完整分支的检出)会修改暂存区:
- 危险性?: Yes!
- 行数:
- ~15
- ~5
- ~15
- Conceptual Quiz (without branching)
- Conceptual Quiz (with branching)
branch
- 用法:
java gitlet.Main branch [分支名称] - 描述: 创建一个具有给定名称的新分支,并将其指向当前的头部提交。分支只是对提交节点的引用(一个SHA-1标识符)的名称。该命令不会立即切换到新创建的分支(就像真实的Git一样)。在调用分支之前,您的代码应该使用一个名为“master”的默认分支运行。
- 运行时间: 相对于任何重要度量,应该是常量。
- 失败情况: 如果已经存在具有给定名称的分支,则打印错误消息
A branch with that name already exists.。 - 危险性: 否
- 我们的行数: ~10
好的,让我们详细看看分支命令的作用。假设我们的状态如下所示:
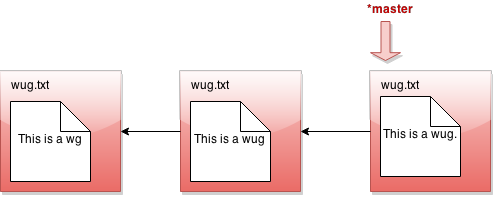
现在我们调用 java gitlet.Main branch cool-beans。然后我们得到这个:
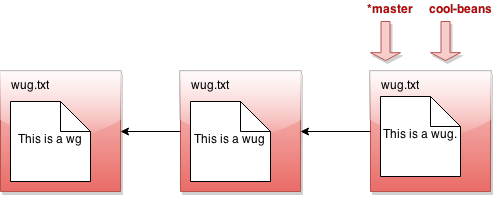
嗯… 没什么大不了的。让我们切换到名为 java gitlet.Main checkout cool-beans 的分支:
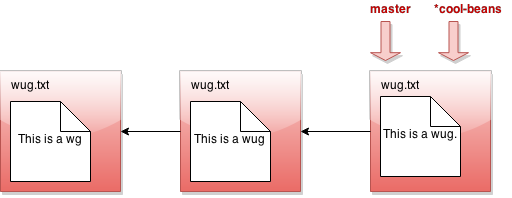
又什么都没发生?!好吧,假设我们现在进行一次提交。修改一些文件,然后 java gitlet.Main add... 然后 java gitlet.Main commit...
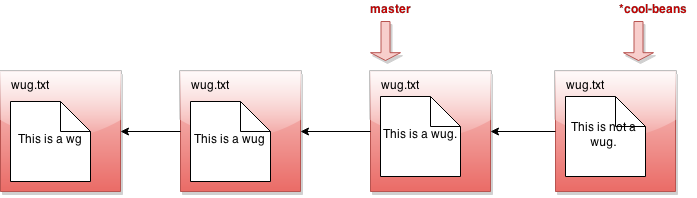
我被告知会有分支。但我看到的只是一条直线。发生了什么?也许我应该回到我的另一个分支 java gitlet.Main checkout master:
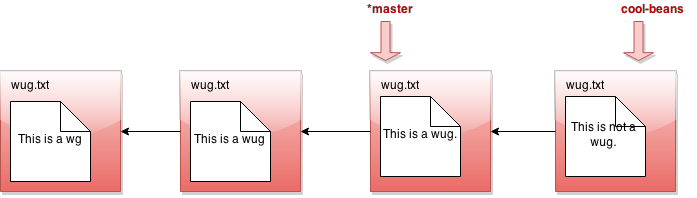
现在我做一个提交…
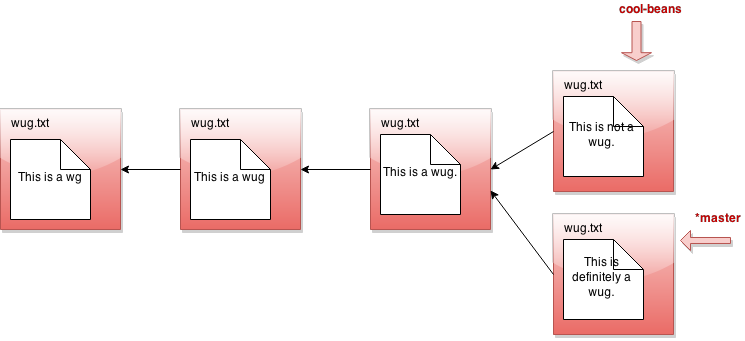
呼!这就是分支的整个理念。你明白发生了什么了吗?创建分支的所有操作只是为我们提供了一个新的指针。在任何给定时间,这些指针中的一个被认为是当前活动的指针,也称为HEAD指针(用 * 标记)。我们可以使用 checkout [分支名称] 切换当前活动的HEAD指针。每当我们提交时,这意味着我们将一个子提交添加到当前活动的HEAD提交中,即使已经存在一个子提交。这自然地创建了分支行为,因为现在一个提交可以有多个子提交。
可以在这里找到关于分支的视频示例和概述。
确保您的branch、checkout和commit的行为与我们上面描述的一致。这是Gitlet的核心功能,许多其他命令都将依赖于它。如果任何核心功能出现问题,我们的自动化测试中的很多测试将无法正常工作!
rm-branch
- Usage:
java gitlet.Main rm-branch [branch name] - Description: 删除具有给定名称的分支。这只是删除与分支关联的指针;不意味着删除在该分支下创建的所有提交,或者类似的操作。
- 运行时间: 相对于任何重要度量,应该是常量。
- 失败情况: 如果具有给定名称的分支不存在,则中止。打印错误消息
A branch with that name does not exist.如果尝试删除当前正在使用的分支,则中止,打印错误消息Cannot remove the current branch.。 - 危险性: 否
- 我们的行数: ~15
reset
Usage:
java gitlet.Main reset [commit id]Description: 检出给定提交跟踪的所有文件。删除不在该提交中的跟踪文件。还将当前分支的头指针移动到该提交节点。有关在使用 reset 后头指针的变化示例,请参见简介。
[commit id]可以像checkout一样缩写。暂存区被清除。该命令实质上是将当前分支头切换到任意提交的checkout命令。运行时间: 相对于给定提交快照中跟踪的文件总大小,应该是线性的。相对于涉及提交数量的任何度量,应该是常量的。
失败情况
: 如果不存在具有给定 id 的提交,则打印
1
No commit with that id exists.
如果当前分支中存在一个未跟踪的工作文件,并且将被重置覆盖,则打印
There is an untracked file in the way; delete it, or add and commit it first.并退出;在执行任何其他操作之前执行此检查。
危险性: 是的!
与真实 git 的差异: 此命令最接近使用
--hard选项,如git reset --hard [commit hash]。我们的行数: ~10 我们是如何得到如此小的行数的?请回想一下,你应该重用你的代码 :)
merge
Usage:
java gitlet.Main merge [branch name]Description: 将给定分支中的文件合并到当前分支中。这个方法有点复杂,所以这里有一个更详细的描述:
- 首先考虑当前分支和给定分支的分割点。例如,如果
master是当前分支,branch是给定分支: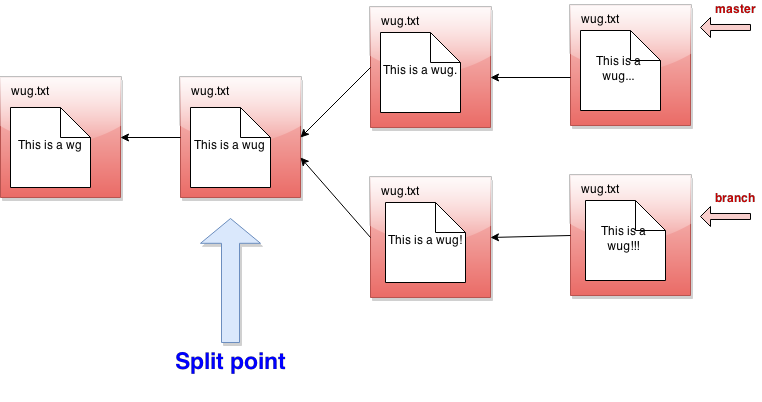 分割点是当前分支和给定分支头部的 最新公共祖先:- 一个 公共祖先 是一个从两个分支头部到达的路径(有0个或更多个父指针)。- 一个 最新 公共祖先是不是其他公共祖先的祖先的公共祖先。例如,尽管上图中最左边的提交是
分割点是当前分支和给定分支头部的 最新公共祖先:- 一个 公共祖先 是一个从两个分支头部到达的路径(有0个或更多个父指针)。- 一个 最新 公共祖先是不是其他公共祖先的祖先的公共祖先。例如,尽管上图中最左边的提交是 master和branch的公共祖先,但它也是右侧紧邻的提交的祖先,因此它不是最新的公共祖先。如果分割点 是 与给定分支相同的提交,则我们不执行任何操作;合并已完成,并以消息Given branch is an ancestor of the current branch.结束。如果分割点是当前分支,则效果是检出给定分支,并在打印消息Current branch fast-forwarded.后结束。否则,我们继续执行下面的步骤。
- 自分割点以来在给定分支中被 修改,但在当前分支中自分割点以来未被修改的任何文件都应更改为给定分支中它们的版本(从给定分支前端的提交中检出)。然后,这些文件应自动进入暂存区。为了澄清,如果一个文件“在给定分支中自分割点以来被修改”,这意味着文件的版本如同在给定分支前端的提交中存在,内容与分割点处的文件版本不同。记住:blob 是内容可寻址的!
- 在当前分支中被修改但在给定分支自分割点以来未被修改的任何文件都应保持不变。
- 在当前分支和给定分支中以相同方式被修改的任何文件(即,这些文件现在都具有相同的内容或都被移除)都会被合并后保持不变。如果一个文件在当前分支和给定分支中都被移除,但是工作目录中存在同名文件,则该文件将被保持不变,并继续在合并中处于缺失状态(未被跟踪也未被暂存)。
- 在分割点处未出现但仅在当前分支中出现的任何文件都应保持不变。
- 在分割点处未出现但仅在给定分支中出现的任何文件都应被检出并暂存。
- 在分割点处存在但在当前分支中未被修改并且在给定分支中不存在的任何文件都应该被移除(并且未被跟踪)。
- 在分割点处存在但在给定分支中未被修改并且在当前分支中不存在的任何文件都应保持不存在。
- 在当前分支和给定分支中以不同方式被修改的任何文件都会冲突。“以不同方式被修改”可以意味着两者的内容都发生了变化且不同,或者一个文件的内容发生了变化而另一个文件被删除,或者文件在分割点处不存在,并且在给定分支和当前分支中具有不同的内容。在这种情况下,使用以下内容替换冲突文件的内容:
- 首先考虑当前分支和给定分支的分割点。例如,如果
1 | <<<<<<< HEAD |
(用指定文件的内容替换“current branch 中文件的内容”和“given branch 中文件的内容”)。并暂存结果。在这里使用直接连接。在文件末尾没有换行符的情况下,你可能会得到类似这样的内容:
1 | <<<<<<< HEAD |
这没问题;那些因为不知道换行符和行分隔符的区别而产生非标准、病态文件的人应该得到他们所得到的。
一旦根据上述更新文件,并且分割点不是当前分支或给定分支,合并将自动提交,并使用日志消息 Merged [given branch name] into [current branch name].。然后,如果合并遇到冲突,打印消息 Encountered a merge conflict. 在终端上(而不是日志上)。合并提交与其他提交不同:它们记录了当前分支头部(称为第一个父节点)和传递给合并命令行的分支头部两者作为父节点。
有关该命令的视频演示可以在此处找到。
运行时间: O(NlgN+D),其中 N 是两个分支的祖先提交的总数,D 是这些提交下所有文件中的数据总量。
失败情况: 如果存在已暂存的添加或删除,打印错误消息
You have uncommitted changes.并退出。如果不存在具有给定名称的分支,打印错误消息A branch with that name does not exist.如果尝试合并自身的分支,打印错误消息Cannot merge a branch with itself.如果合并会生成错误,因为所做的提交中没有更改
骨架
骨架相当简陋,大部分类都是空的。我们提供了有用的 javadoc 注释,暗示了每个文件中可能想要包含的内容。您应该遵循类似于 Capers 的方法,其中您的 Main 类本身不做太多工作,而是根据 args 简单地调用其他方法。您完全可以删除其他类或添加自己的类,但是 Main 类应该保留,否则我们的测试将无法找到您的代码。
如果您不确定从何处开始,我们建议查看Lab 6: Canine Capers。
设计文档
由于这次您不是从一个实质性的骨架中工作,我们要求每个人提交一个描述其实现策略的设计文档。这不是评分标准,但在我们的办公时间或 Gitbug 上提供帮助之前,您必须有一个最新和完整的设计文档。如果您没有或者它不是最新的/不完整的,我们将无法帮助您。这是为了我们双方考虑的:通过编写设计文档,您已经为如何解决任务制定了一条路线图。如果您需要帮助创建设计文档,我们可以帮忙:)这里有一些指导方针,以及来自 Capers 实验的示例。
关于项目的杂项事项
哇!刚才那些命令真是够多的。但别担心,不是所有的命令都同样困难。对于每个命令,你可以看到我们在每个部分所用的大致行数(这仅计算与该命令相关的代码 - 不会重复计算在多个命令中重复使用的代码)。你不必担心与我们的解决方案完全匹配,但希望它能让你了解每个命令相对消耗的时间。合并是一个比其他命令更长的命令,所以不要把它留到最后一刻!
这是一个雄心勃勃的项目,如果你感到不知从何处开始,也不足为奇。因此,请随意比平常更密切地与他人合作,但需要注意以下几点:
- 在你的
gitlet/Main.java文件的开头附近的注释中承认所有合作者。 - 不要分享具体的代码;所有合作者必须生成自己的算法版本,以便我们可以看到它们的不同。
Ed的讨论串通常在Gitlet中变得非常长,但它们充满了关于特定提交方法的非常好的对话和讨论。在这个项目中,你应该利用课程规模的大小,看看是否可以找到与你在讨论串上有类似问题的人。你的问题很有可能不是那么独特,以至于没有其他人遇到过(除非它是与你的设计相关的错误,在这种情况下,你应该提交一个 Gitbug)。
到目前为止,这个规范已经给了你足够的信息来开始项目了。但为了帮助你更多一点,还有一些你应该知道的事情:
处理文件
该项目需要读写文件。为了执行这些操作,你可能会发现 java.io.File 和 java.nio.file.Files 类有所帮助。实际上,你可能会发现 java.io 和 java.nio 包中的各种东西都很有用。确保阅读我们为你编写的 gitlet.Utils 包中的其他内容。如果你通过所有这些内容进行一些挖掘,你可能会找到一些可以使该项目的 I/O 部分大大简化的方法!一个警告:如果你发现自己在使用读取器、写入器、扫描器或流,那么你正在使事情变得比必要的更复杂。
序列化细节
如果你考虑一下 Gitlet,你会注意到每次运行程序时只能运行一个命令。为了成功完成你的版本控制系统,你需要记住跨多个程序运行的 commit 树。这意味着你不仅需要设计一组在执行期间代表内部 Gitlet 结构的类,还需要一种类似的表示方式作为你的 .gitlet 目录中的文件,这些文件将跨多次程序运行。
正如前面所示,这样做的方便方法是对你将永久存储在文件中的运行时对象进行序列化。Java 运行时会完成所有工作,找出需要转换为字节的字段以及如何进行转换。
你已经在 lab6 中做过序列化了,所以我们不会在这里重复信息。如果你对序列化的某些方面仍然感到困惑,请重新阅读 lab6 规范的相关部分,并检查一下你的代码。
然而,有一个令人讨厌的细微之处需要注意:Java 序列化遵循指针。也就是说,不仅传递给 writeObject 的对象被序列化和写入,它指向的任何对象也被序列化和写入。例如,如果你的提交的内部表示将父提交表示为指向其他提交对象的指针,那么写入分支的头部将会写入整个提交子图中的所有提交(和 blob)到一个文件中,这通常不是你想要的。为了避免这种情况,不要在你的运行时对象中使用 Java 指针来引用提交和 blob,而是使用 SHA-1 哈希字符串。在这些字符串和运行时对象之间保持一个运行时映射。你在 Gitlet 运行时创建并填充这个映射,但永远不会将其读取或写入文件中。
为了避免这种情况,不要在你的运行时对象中使用 Java 指针来引用提交和 blob,而是使用 SHA-1 哈希字符串。在这些字符串和运行时对象之间保持一个运行时映射。你在 Gitlet 运行时创建并填充这个映射,但永远不会将其读取或写入文件中。
你可能会发现有一些便利,对提交进行多余的指针,以避免每次查找时所需的麻烦和执行时间。你可以将这样的指针存储在你的对象中,同时避免将它们写出去,方法是声明它们为“瞬态”,如下所示:
1 | private transient MyCommitType parent1; |
这样的字段将不会被序列化,并且在反序列化时,将被设置为它们的默认值(对于引用类型为 null)。当读取包含瞬态字段的对象时,你必须小心地将瞬态字段设置为适当的值
。
不幸的是,用文本编辑器查看你的程序产生的序列化文件(用于调试目的)会非常没有启示性;内容以 Java 的私有序列化编码进行编码。因此,我们提供了一个简单的调试工具程序,你可能会觉得有用:gitlet.DumpObj。详细信息请参阅 gitlet/DumpObj.java 的 Javadoc 注释。
测试
你应该阅读整个这个部分,尽管 视频 也是可用的,方便你查看。
像往常一样,测试是项目的一部分。确保为每个命令提供自己的集成测试,覆盖所有指定的功能。此外,随意添加任何单元测试。我们没有提供任何单元测试,因为单元测试高度依赖于你的实现。
我们提供了一个测试程序,可以相对容易地编写集成测试:testing/tester.py。这个程序会解释带有 .in 扩展名的测试文件。你可以使用以下命令运行所有测试:
1 | make check |
如果你想要有关失败测试的其他信息,比如你的程序输出了什么,运行:
1 | make check TESTER_FLAGS="--verbose" |
如果你想要运行单个测试,在 testing 子目录中运行命令:
1 | python3 tester.py --verbose FILE.in ... |
其中 FILE.in ... 是你想要检查的特定 .in 文件列表。
小心运行此命令,因为它不会重新编译你的代码。每次运行 python 命令之前,你都必须先编译你的代码(通过 make)。
命令
1 | python3 tester.py --verbose --keep FILE.in |
将在测试脚本检测到错误的地方保留 tester.py 产生的目录,以便你可以检查它的文件。如果你的测试没有出错,那么该目录仍然会保留下来,其中包含所有东西的最终内容。
实际上,测试程序实现了一个非常简单的特定领域语言(DSL),其中包含以下命令:
- 设置或从测试目录中删除文件;
- 运行
java gitlet.Main; - 检查 Gitlet 的输出与特定输出或描述可能输出的正则表达式;
- 检查文件的存在、不存在和内容。运行命令
1 | python3 testing/tester.py |
(没有操作数,如所示)将提供一条消息,记录此语言的内容。我们在 testing/samples 目录中提供了一些示例。不要将你自己的测试放在该子目录中;将它们放在与我们的测试不同的地方,这样你就不会混淆我们的测试和你的测试(后者可能有错误!)。将所有你的 .in 文件放在 testing 目录下的另一个名为 student_tests 的文件夹中。在骨架中,该文件夹为空。
我们已经在 Makefile 中添加了一些内容,以调整人们的设置之间的差异。如果你的系统调用 Python 3 的命令只是 python,你仍然可以使用我们的 Makefile,方法是使用
1 | make PYTHON=python check |
你可以使用额外的标志向 tester.py 传递额外的标志,例如:
1 | make TESTER_FLAGS="--keep --verbose" |
对员工解决方案进行测试
截至 2 月 28 日星期日,现在你可以使用员工解决方案来验证你对命令的理解以及验证你自己的测试!这里有一个指南。
理解集成测试
在 Gitbugs 上向我们请求帮助,或者在办公时间来接受帮助时,我们将首先要求你提供一个失败的测试,因此你学会在这个项目中编写测试非常重要。我们已经做了很多工作,使这一过程尽可能轻松,请花时间阅读本节,以便理解提供的测试并自己编写良好的测试。
集成测试的格式与 Capers 的测试类似。如果你不知道 Capers 的集成测试(即 .in 文件)是如何工作的,请先阅读 capers 规范 中的该部分。
提供的测试远非全面,你肯定需要编写自己的测试才能获得项目的满分。为了编写测试,让我们首先了解一下这一切是如何工作的。
这是 testing 目录的结构:
1 | . |
就像 Capers 一样,这些测试通过在 testing 目录内创建临时目录并运行 .in 文件中指定的命令来工作。如果使用 --keep 标志,则该临时目录将在测试完成后保留,以便你可以检查它。
与 Capers 不同,我们需要处理工作目录中文件的 内容。因此,在这个 testing 文件夹中,我们有一个名为 src 的额外文件夹。该目录存储了许多预先填充的 .txt 文件,其中包含我们需要的特定内容。稍后我们会回到这一点,但现在只需知道 src 存储了实际的文件内容。samples 包含示例测试的 .in 文件(即检查点测试)。当你创建自己的测试时,应将它们添加到最初为空的 student_tests 文件夹中。
.in 文件在 Gitlet 中有更多的功能。下面是来自 tester.py 文件的说明:
1 | # ... 一个注释,没有任何效果。 |
不必担心上述说明中提到的 Python 正则表达式的东西:我们将向你展示它很简单,甚至会通过一个例子演示如何使用它。
让我们走一遍测试,看看从头到尾发生了什么。让我们检查 test02-basic-checkout.in。
示例测试
当我们第一次运行此测试时,将创建一个最初为空的临时目录。我们的目录结构现在是:
1 | . |
这个临时目录是用于此测试执行的 Gitlet 仓库,因此我们将在那里添加东西并运行所有的 Gitlet 命令。如果第二次运行测试而不删除目录,则会创建一个名为 test02-basic-checkout_1 的新目录,依此类推。每次测试的执行都使用它
自己的目录,因此不必担心测试之间的干扰。
测试的第一行是一个注释,所以我们忽略它。
接下来的部分是:
1 | > init |
这不应该有任何输出,因为我们可以通过此部分的第一行与带有 > 的行和带有 <<< 的行之间没有文本来判断。但是,正如我们所知道的,这应该创建一个 .gitlet 文件夹。因此,我们的目录结构现在是:
1 | . |
接下来的部分是:
1 | + wug.txt wug.txt |
这一行使用 + 命令。它将右侧的文件从 src 目录复制其内容到临时目录中的左侧文件(如果不存在,则创建)。它们的名字相同,但由于它们位于不同的目录中,这并不重要。在执行此命令后,我们的目录结构现在是:
1 | . |
现在我们看到了 src 目录的用途:它包含测试可以使用的文件内容,以便设置 Gitlet 仓库。如果你想要向文件添加特殊内容,你应该将这些内容添加到 src 中的一个命名合适的文件中,然后使用与此处相同的 + 命令。很容易混淆参数的顺序,所以确保右侧引用 src 目录中的文件,而左侧引用临时目录中的文件。
接下来的部分是:
1 | > add wug.txt |
正如你所看到的,这应该没有任何输出。wug.txt 文件现在在临时目录中准备添加。此时,你的目录结构可能会在 .gitlet 目录内部发生变化,因为你需要以某种方式持久保存 wug.txt 准备添加的事实。
接下来的部分是:
1 | > commit "added wug" |
同样,没有输出,你的目录结构可能会在 .gitlet 中发生变化。
接下来的部分是:
1 | + wug.txt notwug.txt |
由于 wug.txt 已经存在于我们的临时目录中,其内容将更改为 src/notwug.txt 中的任何内容。
接下来是
1 | > checkout -- wug.txt |
同样,没有输出。然而,它应该将我们临时目录中的 wug.txt 的内容更改回原始内容,即 src/wug.txt 的内容。下一个命令是断言:
1 | = wug.txt wug.txt |
这是一个断言:如果左侧的文件(再次强调,这是在临时目录中)与右侧的文件(来自 src 目录)的内容不完全相同,则测试脚本将报错并说你的文件内容不正确。
还有两种其他可用于断言的命令:
1 | E NAME |
将断言临时目录中存在一个名为 NAME 的文件/文件夹。它不检查内容,只检查它是否存在。如果不存在具有该名称的文件/文件夹,则测试将失败。
1 | * NAME |
断言临时目录中不存在名为 NAME 的文件/文件夹。如果存在具有该名称的文件/文件夹,则测试将失败。
这恰好是测试的最后一行,所以测试结束了。如果提供了 --keep 标志,则临时目录将保留,否则将被删除。如果你怀疑你的 .gitlet 目录没有被正确设置或者存在一些持久性问题,你可能会希望保留它。
测试准备
正如你很快会发现的,测试一个特定命令可能需要很多重复的设置:例如,如果你正在测试 checkout 命令,你需要:
- 初始化一个 Gitlet 仓库
- 使用某个版本(v1)在提交中创建一个文件
- 使用该文件的另一个版本(v2)在另一个提交中创建一个文件
- 将该文件检出到 v1
如果你想测试在第二个提交中未跟踪但在第一个提交中已跟踪的文件,可能还需要更多的设置。
因此,你可以通过在一个文件中添加所有这些设置,并使用 I 命令来节省时间。假设我们在这里这样做:
1 | # 初始化,添加并提交一个文件。 |
我们应该将此文件与其他测试一起放在 samples 目录中,但是将文件扩展名设置为 .inc,
所以也许我们命名为 samples/commit_setup.inc。如果我们给它的文件扩展名是 .in,那么我们的测试脚本将错误地将其视为一个测试并尝试单独运行它。在我们的实际测试中,我们简单地使用命令:
1 | I commit_setup.inc |
这将使测试脚本运行该文件中的所有命令,并保留它创建的临时目录。这样可以使你的测试相对较短,因此更容易阅读。
我们包含了一个名为 definitions.inc 的 .inc 文件,它将为你设置方便的模式。让我们了解一下模式是什么。
匹配模式输出
测试最令人困惑的部分是 log 输出。有几个原因:
- 提交 SHA 将随着修改代码和哈希更多内容而更改,因此你必须不断修改测试以跟上 SHA 的变化。
- 你的日期将每次更改,因为时间只会向前推移。
- 它会使测试变得很长。
我们实际上并不在乎精确的文本:只要有一些 SHA 和正确的日期格式的东西即可。基于这个原因,我们的测试使用模式匹配。
这不是你需要理解的概念,但在高层次上,我们为一些文本(例如提交 SHA)定义一个模式,然后仅检查输出是否具有该模式(不关心实际的字母和数字)。
下面是你如何为 log 输出创建预期输出并检查它是否匹配模式:
1 | # 首先从我们的设置中“导入”模式定义 |
我们看到的部分与正常的 Gitlet 命令相同,除了它以 <<<* 结尾,这告诉测试脚本使用模式。模式被包含在 ${PATTERN_NAME} 中。
所有模式都定义在 samples/definitions.inc 中。你不需要理解实际模式,只需知道它匹配的内容。例如,HEADER 匹配提交的头部,应该类似于:
1 | commit fc26c386f550fc17a0d4d359d70bae33c47c54b9 |
这只是一个随机的提交 SHA。
因此,当我们为此测试创建预期输出时,我们需要知道日志中有多少条目以及提交消息是什么。
你可以使用类似的方法来进行 status 命令的测试:
1 | I definitions.inc |
我们在这里使用的模式是 ARBLINES,它是任意行。如果你确实关心哪些文件未跟踪,那么你可以在这里添加,而不使用模式,但也许我们更感兴趣的是看到 g.txt 被准备添加。
注意分支 master 上的 \*。回想一下,在 status 命令中,应该使用 * 来标记 HEAD 分支。如果你使用模式,你需要在预期输出中将这个 * 替换为 \*。这是在课程范围之外的事情,但它被称为“转义”星号。如果你不使用模式(即你的命令以 <<< 而不是 <<<* 结尾),那么你可以使用没有 \ 的 *。
对于这些模式,你可以进行最后一件事是“保存”匹配的部分。警告:这似乎像是魔法,我们根本不关心你是否理解这是如何工作的,只知道它可以并且对你可用。你可以从我们提供的测试中复制并粘贴相关部分,因此你不需要太担心从头开始制作这些。说完了,让我们看看这是什么。
如果你正在执行 checkout 命令,你需要使用 SHA 标识符来指定要检出到/从哪个提交。但是记住,我们使用了模式,所以在创建测试时我们实际上不知道 SHA 标识符。这是有问题的。我们将使用 test04-prev-checkout.in 来看看你如何“捕获”或“保存”SHA:
1 | I definitions.inc |
这将设置 UID(SHA)在 log 命令后被捕获。因此,在运行此命令后,我们可以使用 D 命令将 UID 定义为变量:
1 | # 第二个版本的 UID |
注意编号是反向的:编号从 1 开始,并从日志的顶部开始。这就是为什么当前版本(即第二个版本)被定义为 "${1}"。我们不关心初始提交,所以我们不会费心捕获
它的 SHA。
这里我们保存了两个 UID,因为我们知道第一个版本有内容,第二个版本的内容被我们更改了。在实际测试中,这可能是一个更复杂的操作,但这是一个示例。我们通过在 ${} 中引用 UID 来使用 UID。我们可以将 UID 直接传递给 Gitlet 命令,而无需知道它是什么:
1 | > checkout ${UID1} -- wug.txt |
这将检出到第一个版本,我们知道这是第一个版本,因为我们已经捕获了它的 UID。同样,我们可以使用模式匹配来确定这一切是否正确。
这就是所有关于测试的全部。请确保每个测试都是自包含的,并且应该在没有任何依赖关系的情况下运行。每个测试应该设置它自己的仓库,并假设没有之前的测试。毫无疑问,测试脚本和测试文件中的注释将是你的好朋友,所以不要犹豫去添加它们。
一些额外的技巧
你会发现在测试中有些模式的使用频率更高。例如 UID,因为它用于检出命令。另一个常见的模式是日期和时间戳。这些在 log 输出中出现,以及当你创建提交时,它们将被包含在输出中。这是一个处理日期的示例:
1 | D DATE "Wed Apr 10 12:00:00 2024 -0700" |
它将日期设置为指定的日期。这将允许你在测试中创建提交,并检查它们的日期是否正确。同样,如果你想要检查 SHA 以确保每个提交具有唯一的 SHA,你可以使用模式匹配来匹配提交 SHA。
1 | D COMMIT_HEAD "[0-9a-f]{40}" |
然后,将它放在你的 log 输出中:
1 | === |
最后,我要强调测试文件的封闭性和自包含性。一个测试应该是独立于其他测试的,这意味着你的测试应该是互相独立的,不应该依赖于其他测试的结果。这是因为在运行测试套件时,测试的顺序可能会发生变化,这样可以确保你的测试可以单独运行,而不必担心它们所依赖的其他测试。
远程操作(额外学分)
这个项目的主要目标是模仿 git 的本地功能。这些功能很有用,因为它们允许你备份自己的文件并维护它们的多个版本。然而,git 的真正强大之处在于它的远程功能,允许与其他人通过互联网进行协作。关键在于你和你的朋友都可以在一个代码库上进行协作。如果你对文件进行了更改,你可以将它们发送给你的朋友,反之亦然。你们两个都可以访问所有你们所做更改的共享历史记录。
为了获得额外学分,实现一些基本的远程命令:即 add-remote、rm-remote、push、fetch 和 pull。完成它们将获得 64 分额外学分。在完成项目的其余部分之前,请不要尝试或计划额外学分。
根据你设计项目的灵活性,64 分额外学分可能不值得去做这一部分所需的努力。我们并不期望每个人都去做。我们的重点将是帮助学生完成主要项目;如果你在做额外学分,我们希望你能够比大多数学生更独立一些。
命令
关于远程命令有几点说明:
- 不会对执行时间进行评分。为了你自己的提高,请不要做任何荒谬的事情。
- 所有命令都是从它们的 git 等效版本大幅简化的,因此通常不注明与 git 的具体区别。但要注意它们的存在。
现在让我们来看看这些命令:
add-remote
- 用法:
java gitlet.Main add-remote [远程名称] [远程目录名称]/.gitlet - 描述:将给定的登录信息保存在给定的远程名称下。尝试从给定的远程名称推送或拉取将尝试使用此
.gitlet目录。通过编写,例如,java gitlet.Main add-remote other ../testing/otherdir/.gitlet,你可以提供从所有位置(在你的家用计算机上或评分程序的软件中)工作的远程测试。在这些命令中始终使用正斜杠。让你的程序将所有正斜杠转换为路径分隔符(Unix 上的正斜杠和 Windows 上的反斜杠)。Java 友好地定义了类变量java.io.File.separator作为此字符。 - 失败情况:如果已经存在具有给定名称的远程,则打印错误消息:
已经存在该名称的远程。你不必检查用户名和服务器信息是否合法。 - 危险吗?:不。
rm-remote
- 用法:
java gitlet.Main rm-remote [远程名称] - 描述:删除与给定远程名称关联的信息。这里的想法是,如果你曾经想要更改你添加的远程,你必须首先删除它,然后重新添加它。
- 失败情况:如果具有给定名称的远程不存在,则打印错误消息:
不存在具有该名称的远程。 - 危险吗?:不。
push
用法:
java gitlet.Main push [远程名称] [远程分支名称]描述:尝试将当前分支的提交追加到给定远程的给定分支的末尾。细节:
此命令仅在远程分支的头部在当前本地头部的历史记录中时才起作用,这意味着本地分支包含一些在远程分支未来的提交。在这种情况下,将未来的提交追加到远程分支。然后,远程应该重置到附加的提交的前端(因此其头部将与本地头部相同)。这称为快进。
如果远程机器上的 Gitlet 系统存在但没有输入分支,则简单地将该分支添加到远程 Gitlet。
失败情况:如果远程分支的头部不在当前本地头部的历史记录中,则打印错误消息
请在推送之前拉取远程更改。如果远程.gitlet目录不存在,则打印未找到远程目录。危险吗?:不。
fetch
- 用法:
java gitlet.Main fetch [远程名称] [远程分支名称] - 描述:将远程 Gitlet 仓库中的提交下载到本地 Gitlet 仓库中。基本上,这将从远程仓库中的给定分支复制所有提交和 blob(在当前仓库中尚不存在的)到本地
.gitlet中的名为[远程名称]/[远程分支名称]的分支中(与真实的 Git 一样),将[远程名称]/[远程分支名称]指向头提交(因此将分支的内容从远程仓库复制到当前仓库)。如果此分支之前不存在,则在本地仓库中创建此分支。 - 失败情况:如果远程 Gitlet 仓库没有给定的分支名称,则打印错误消息
该远程没有该分支。如果远程.gitlet目录不存在,则打印未找到远程目录。 - **危险
吗?**:不。
pull
- 用法:
java gitlet.Main pull [远程名称] [远程分支名称] - 描述:像
fetch命令一样获取分支[远程名称]/[远程分支名称],然后将该获取合并到当前分支。 - 失败情况:
fetch和merge命令的失败情况。 - 危险吗?:是的!
I. 避免的事情
根据经验,有一些做法会导致程序不工作,难以找到的错误,有时不可重复(“Heisenbugs”)。
- 由于你可能会在文件中保存各种信息(例如提交),你可能会倾向于使用显然方便的文件系统操作(例如列出目录)来对它们进行排序。要小心。例如,
File.list和File.listFiles等方法以未定义的顺序生成文件名。如果你使用它们来实现log命令,特别是,你可能会得到随机结果。 - 特别是 Windows 用户应该注意,文件分隔符字符是 Unix(或 MacOS)上的
/,在 Windows 上是‘\’。因此,如果你通过将一些目录名称和文件名与显式的/或\连接起来来形成文件名,在你的程序中,你可以确保它不会在一个系统或另一个系统上工作。Java 提供了一个系统相关的文件分隔符字符(System.getProperty("file.separator")),或者你可以使用多参数构造函数来创建File。 - 在序列化时要小心使用
HashMap!HashMap内部的事物顺序是不确定的。解决方案是使用TreeMap,它将始终具有相同的顺序。更多详情在这里
J. 致谢
感谢 Alicia Luengo、Josh Hug、Sarah Kim、Austin Chen、Andrew Huang、Yan Zhao、Matthew Chow,特别是 Alan Yao、Daniel Nguyen 和 Armani Ferrante,提供了此项目的反馈。感谢 git 的强大。
此项目在很大程度上受到 [这篇][Nilsson Article] 由 Philip Nilsson 撰写的优秀文章的启发。
此项目由 Joseph Moghadam 创建。Paul Hilfinger 分别在 2015 年秋季、2017 年秋季和 2019 年秋季进行了修改。



