CS61B学习笔记(五)--链表基础的列表(2.2,2.3)
2.2 SLList ·拥抱61B — 2.2 The SLList · Hug61B (gitbooks.io)
2.3 DLList ·拥抱61B — 2.3 The DLList · Hug61B (gitbooks.io)
SLLists
在第 2.1 章中,我们构建了类 IntList ,这是一个列表数据结构,从技术上讲,它可以完成列表可以执行的所有操作。然而,在实践中,它 IntList 使用起来相当笨拙,导致代码难以阅读和维护。
从根本上说,问题在于 IntList 这就是我所说的裸递归数据结构。为了正确使用递归,程序员必须理解和利用递归,即使是简单的列表相关任务。这限制了它对新手程序员的有用性,并可能引入一类全新的棘手错误,程序员可能会遇到这些错误,具体取决于该 IntList 类提供的帮助程序方法类型。
初级版本:
1 | public class SLList { |
IntList和SLList的比较
创建:
1 | IntList L1 = new IntList(5, null); |
隐藏
SLList用户存在空链接的详细信息。
添加节点
SLList:
1 | SLList L = new SLList(15); |
IntList:
1 | IntList L = new IntList(15, null); |
结论
直观地比较这两种数据结构,我们有:( IntList 版本在顶部, SLList 版本在下方)
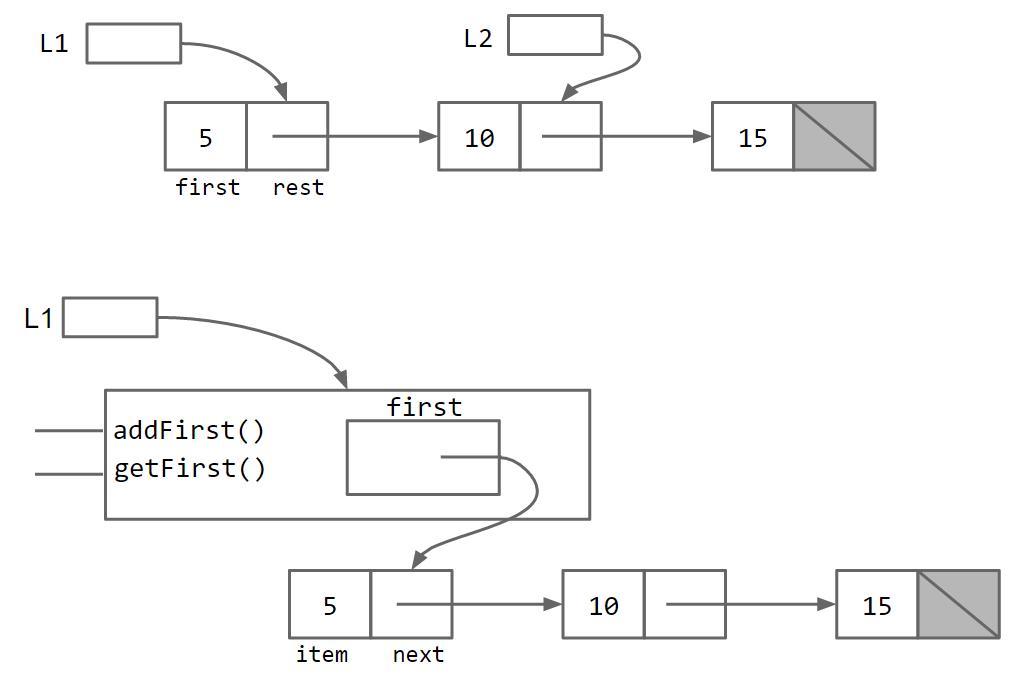
从本质上讲,该 SLList 类充当列表用户和裸递归数据结构之间的中间人。如上 IntList 所述, IntList 用户具有指向 IntList .正如奥维德所说:凡人不能在不死的情况下注视神,所以也许最好在那里 SLList 充当我们的中间人。
SLList提高了代码的抽象性,只提供接口出来,而不是提供具有风险的裸数据
first来获取。
公有与私有
IntList的数据皆为public,没有预留接口来调用。
如果SLList数据也皆为public,那么可以绕过接口直接获取,具有一定风险。
私有变量和方法只能通过同一 .java 文件中的代码访问,例如在本例 SLList.java 中。这意味着像 SLLTroubleMaker 下面的类将无法编译,从而产生 first has private access in SLList 错误。
1 | public class SLLTroubleMaker { |
相比之下, SLList.java 文件内的任何代码都能够访问该 first 变量。
限制访问似乎有点愚蠢。毕竟, private 关键字唯一要做的就是破坏原本编译的程序。然而,在大型软件工程项目中, private 关键字是一个非常宝贵的信号,表明最终用户应该忽略某些代码片段(因此不需要理解)。同样,关键字 public 应该被看作是一种方法可用的声明,并且将永远像现在一样工作。
打个比方,汽车具有某些 public 功能,例如油门和制动踏板。在引擎盖下,有 private 关于它们如何运作的详细信息。在汽油动力汽车中,油门踏板可以控制某种燃油喷射系统,而在电池供电的汽车中,它可以调整输送到电机的电池电量。虽然私人细节可能因汽车而异,但我们预计所有油门踏板都有相同的行为。更改这些会引起用户的极大恐慌,并且很可能会发生可怕的事故。
SList的改进
嵌套IntNode类
由IntList改名而来
目前,我们有两个 .java 文件: IntNode 和 SLList .然而,这真的 IntNode 只是故事中的一个配角 SLList 。
在这种情况下,Java 为我们提供了将一个类声明嵌入到另一个类声明中的能力。语法简单直观:
1 | public class SLList { |
嵌套类对代码性能没有有意义的影响,只是保持代码井井有条的工具。有关嵌套类的更多信息,请参阅 Oracle 的官方文档。
如果嵌套类不需要使用 SLList 的任何实例方法或变量,则可以声明嵌套类 static ,如下所示。将嵌套类声明为 意味着 static 静态类中的方法不能访问封闭类的任何成员。在这种情况下,这意味着 中 IntNode 的任何方法都无法访问 first 、 addFirst 或 getFirst 。
1 | public class SLList { |
这样可以节省一些内存,因为每个 IntNode 都不再需要跟踪如何访问其封闭 SLList 式 .
换句话说,如果你检查上面的代码,你会发现该 IntNode 类从不使用 SLList 的 first 变量 ,也不使用 SLList 的任何方法。因此,我们可以使用 static 关键字,这意味着该 IntNode 类不会引用其 boss,从而节省了少量内存。
一个简单的经验法则是,如果不使用外部类的任何实例成员,请使嵌套类成为静态类。
addLast() and size()
addLast()
1 | /** Adds an item to the end of the list. */ |
对 于 IntList 的 size 递归调用很简单: return 1 + this.rest.size() .对于一个 SLList ,这种方法是没有意义的。 SLList 没有 rest 变量。取而代之的是,我们将使用一种与中间人类一起使用的通用模式,例如 SLList – 我们将创建一个私有帮助程序方法,该方法与底层的裸递归数据结构进行交互。
1 | /** Returns the size of the list starting at IntNode p. */ |
1 | public int size() { |
在这里,我们有两个方法,都命名为 size .这在 Java 中是允许的,因为它们具有不同的参数。我们说两个名称相同但签名不同的方法被重载。有关重载方法的更多信息,请参阅 Java 的官方文档。
另一种方法是在 IntNode 类本身中创建非静态帮助程序方法。这两种方法都很好,尽管我个人更喜欢 IntNode 在类中没有任何方法。
缓存
我们可以发现,当我们需要得到size的值的时候都会重新调用一遍size()函数,这对性能有一定的影响,
假设在大小为 1,000 的列表 size 上需要 2 秒。我们预计,在大小为 1,000,000 的列表中,该 size 方法将需要 2,000 秒,因为计算机必须单步执行列表中 1,000 倍的项目才能到达末尾。对于大型列表来说,使用非常 size 慢的方法是不可接受的,因为我们可以做得更好。
为此,我们可以简单地将一个 size 变量添加到跟踪当前大小的 SLList 类中,从而生成下面的代码。这种保存重要数据以加快检索速度的做法有时称为**缓存(caching)**。
1 | public class SLList { |
这种修改使我们 size 的方法非常快,无论列表有多大。当然,它也会减慢我们的 addFirst 和 addLast 方法的速度,也会增加我们类的使用记忆,但只是微不足道的量。在这种情况下,权衡显然有利于创建大小缓存。
空列表构造引发的空指针异常
我们能够轻松实现一个创建空列表的构造函数。最自然的方法是设置为 first null 如果列表为空。这将产生以下构造函数:
1 | public SLList() { |
不幸的是,如果我们插入到一个空列表中,这会导致我们 addLast 的方法崩溃。由于 first 是 null ,尝试访问 p.next while (p.next != null) 下面会导致空指针异常。
1 | public void addLast(int x) { |
空列表解决方法—哨兵节点
有两种解决方案
(一)为addLast()添加一种特殊情况处理
1 | public void addLast(int x) { |
此解决方案有效,但在必要时应避免使用上面所示的特殊情况代码。人类只有这么多的工作记忆,因此我们希望尽可能地控制复杂性。对于像 这样的简单数据结构 SLList ,特殊情况的数量很少。更复杂的数据结构(如树)可能会变得更加丑陋。
(二)哨兵节点
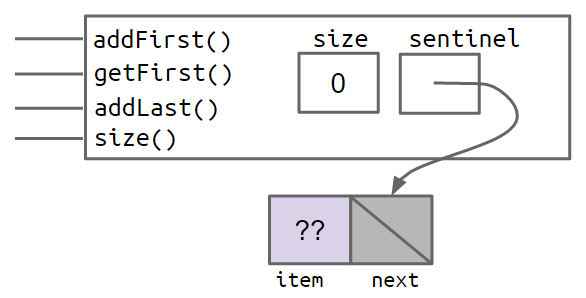
一个更干净的,虽然不那么明显的解决方案是让它变得 SLLists “相同”,即使它们是空的。我们可以通过创建一个始终存在的特殊节点来做到这一点,我们称之为哨兵节点。哨兵节点将持有一个值,我们不会关心它。
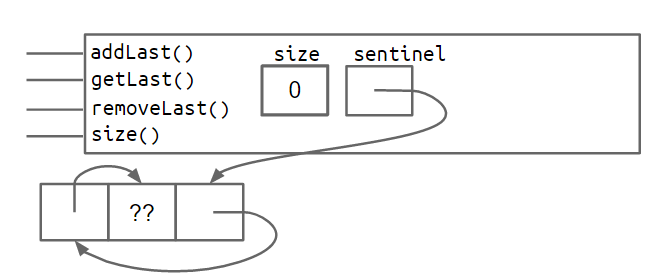
例如,创建的 SLList L = new SLList() 空列表如下所示:
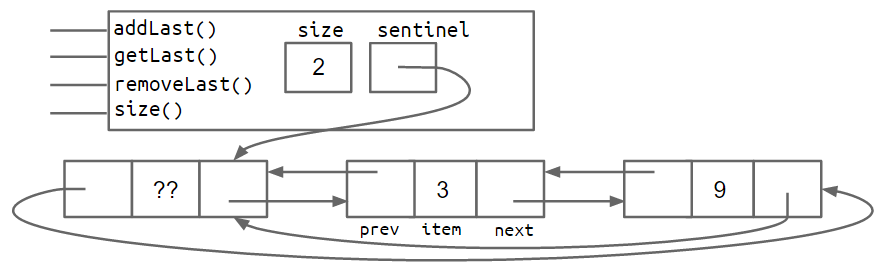
具有项目 5、10 和 15 的 a SLList 如下所示:
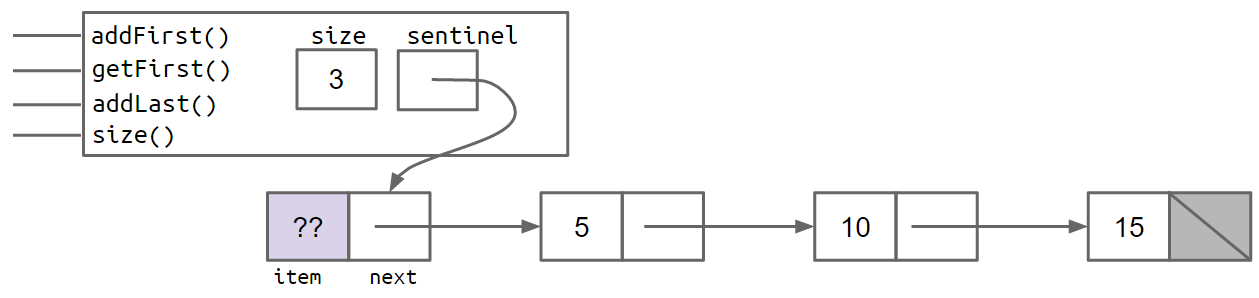
由于 SLList 没有哨兵没有特殊情况,我们可以简单地从我们 addLast 的方法中删除特殊情况,从而得到:
1 | public void addLast(int x) { |
不变量
不变性是关于数据结构的事实,它保证为真(假设代码中没有错误)。
具有哨兵节点的 A SLList 至少具有以下不变量:
- 引用
sentinel始终指向哨兵节点。 - 前面的项(如果存在)始终位于
sentinel.next.item。 - 该
size变量始终是已添加的项的总数。
不变量使推理代码变得更加容易,并且还为您提供了在确保代码正常工作方面要努力实现的具体目标。
SList最终版本
1 | public class SLList { |
DLLists
addLast
考虑上面 addLast(int x) 中的方法。
1 | public void addLast(int x) { |
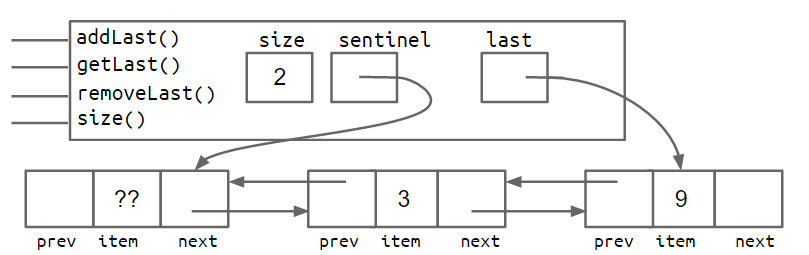
这种方法的问题在于它很慢。对于一个很长的列表,该 addLast 方法必须遍历整个列表,就像我们在第 2.2 章中看到的方法 size 一样。同样,我们可以尝试通过添加变量 last 来加快代码速度,如下所示
考虑表示上述实现的 SLList 框和指针图,其中包括最后一个指针。假设我们想要支持 addLast 、 getLast 和 removeLast 操作。所示结构是否支持快速 addLast 、 getLast 和 removeLast 操作?如果不是,哪些操作很慢?
addLast会很快,但getLastremoveLast会很慢。这是因为在删除最后一个节点后,我们没有简单的方法来获取倒数第二个节点来更新last指针。
SecondToLast
结构的问题在于,删除列表中最后一项的方法本身会很慢。这是因为我们需要首先找到倒数第二项,然后将其下一个指针设置为 null。添加 secondToLast 指针也无济于事,因为这样我们就需要找到列表中倒数第三项,以确保 secondToLast 在删除最后一项后 last 遵守适当的不变量
改进
添加prev指针
解决此问题的最自然方法是为每个 添加一个前一个指针 IntNode ,即
1 | public class IntNode { |
换句话说,我们的列表现在每个节点都有两个链接。此类列表的一个常见术语是“双向链表”,我们简称为 a DLList 。这与第 2.2 章中的单个链表形成鲜明对比,又名 SLList .
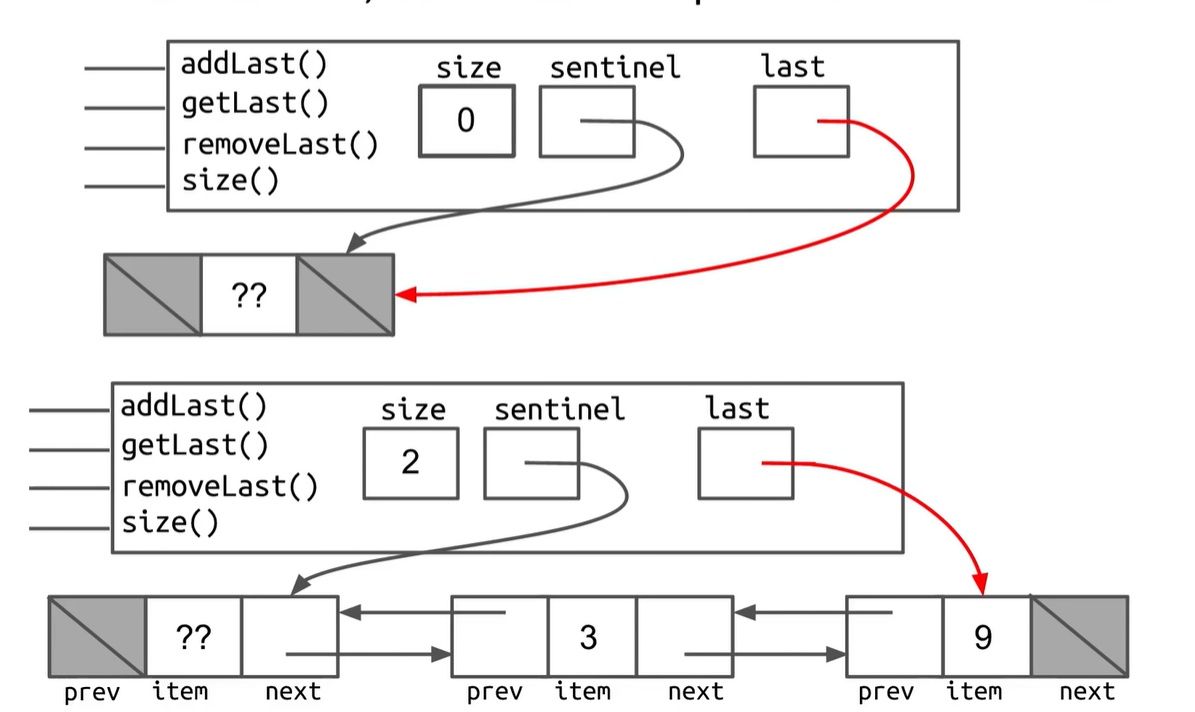
添加这些额外的指针将导致额外的代码复杂性。您将在项目 1 中自行构建一个双向链表,而不是引导您完成它。下面的框图和指针图分别更精确地显示了大小为 0 和大小为 2 的列表的双向链表的外观。
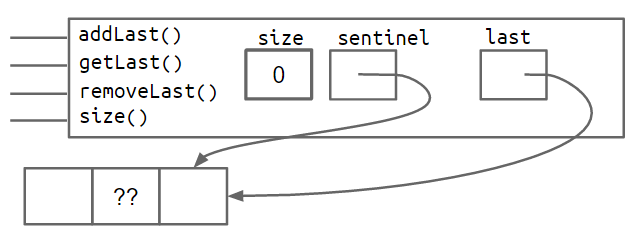
哨兵(Sentinel )改进
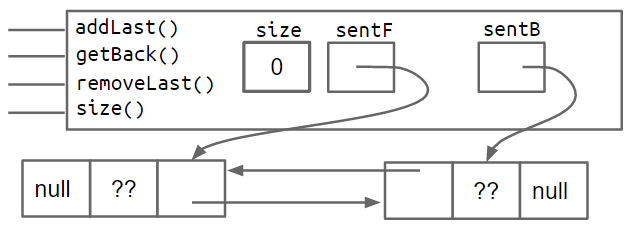
后退指针允许列表支持在恒定时间内添加、获取和删除列表的正面和背面。这种设计存在一个微妙的问题, last 指针有时指向哨兵节点,有时指向真实节点。就像 的非哨兵版本一样 SLList ,这会导致具有特殊情况的代码比我们在第 8 次也是最后一次改进后得到的代码要丑陋得多。(你能想到什么 DLList 方法会有这些特殊情况吗?
对于每个方法我们都要用if语句检查一下last指向的是不是哨兵节点,这就很麻烦。
一种解决方法是将第二个哨兵节点添加到列表的后面。这导致拓扑如下所示,显示为框和指针图。
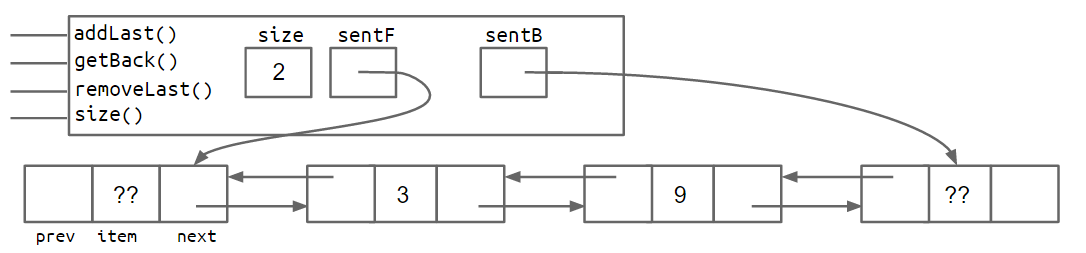
另一种方法是实现列表,使其呈圆形,前指针和后指针共享同一哨兵节点。
双哨兵和圆形哨兵方法都有效,并产生没有丑陋特殊情况的代码,尽管我个人认为圆形哨兵方法更干净,更美观。我们不会讨论这些实泛型 DLList现的细节,因为你将有机会在项目 1 中探索一个或两个。
泛型 DLList
语法一开始有点奇怪。基本思想是,在类声明中的类名称之后,在尖括号内使用任意占位符: <> .然后,在要使用任意类型的任何位置,都可以改用该占位符。
例如,我们 DLList 之前的声明是:
1 | public class DLList { |
可以容纳任何类型的泛型 DLList 如下所示:
1 | public class DLList<BleepBlorp> { |
在这里,BleepBlorp只是我编造的一个名字,你可以用大多数你可能想用的任何其他名字来代替, BleepBlorp 比如 GloopGlop 、、 Horse TelbudorphMulticulus 或其他什么。
现在我们已经定义了该类的泛型版本,我们还必须使用特殊语法来实例化该 DLList 类。为此,我们在声明期间将所需的类型放在尖括号内,并在实例化期间使用空尖括号。例如:
1 | DLList<String> d2 = new DLList<>("hello"); |
由于泛型仅适用于引用类型,因此我们不能将原语放在 int 尖括号内或 double 尖括号内,例如 <int> .取而代之的是,我们使用原始类型的参考版本,在 case 的情况下 int 是 Integer ,例如
关于使用泛型类型还有其他细微差别,但我们会将它们推迟到本书的后面一章,届时您有更多机会自己尝试它们。现在,请使用以下经验法则:
- 在实现数据结构的 .java 文件中,仅在文件最顶部的类名之后指定一次泛型类型名。
- 在其他使用数据结构的 .java 文件中,在声明期间指定所需的特定类型,并在实例化期间使用空菱形运算符。
- 如果需要在基元类型上实例化泛型,请使用
Integer、Character、Long、Short、Byte、Double、Boolean或Float代替其基元等效项。
次要细节:您也可以在实例化时在尖括号内声明类型,尽管这不是必需的,只要您还在同一行上声明一个变量即可。换句话说,下面的代码行是完全有效的,即使右侧的 Integer 代码是多余的。
1 | DLList<Integer> d1 = new DLList<Integer>(5); |



