CS61B学习笔记(六)-数组基础的列表(2.4,2.5)
2.4 Arrays · Hug61B (gitbooks.io)
2.5 The AList · Hug61B (gitbooks.io)
数组
数组基础
数组是一种特殊类型的对象,它由一系列编号的内存盒组成。这与类实例不同,类实例具有命名的内存盒。为了得到数组的第i个元素,我们使用了在HW 0和Project 0中看到的括号表示法,例如 A[i] 得到A的第 i 个元素。
数组包括:
- 一个固定的整数长度N
- 一个由N个存储器盒组成的序列(N =长度),其中所有盒都是相同类型的,编号为0到N - 1。
和类不同,数组没有方法
数组创建
x = new int[3];y = new int[]{1, 2, 3, 4, 5};int[] z = {9, 10, 11, 12, 13};
所有这三种表达法都创建了一个数组。
第一种表示法,用于创建 x ,将创建一个指定长度的数组,并使用默认值填充每个内存框。在本例中,它将创建一个长度为3的数组,并使用默认值 int 0 填充3个框中的每一个。
第二种表示法,用于创建 y ,创建一个数组,其大小正好可以容纳指定的起始值。在本例中,它创建了一个长度为5的数组,其中包含这五个特定的元素。
第三种表示法用于声明和创建 z ,其行为与第二种表示法相同。唯一的区别是它省略了 new 的用法,并且只能在与变量声明组合时使用。
这些符号没有一个比其他符号更好。
数组的访问和修改
下面的代码展示了我们将用于处理数组的所有关键语法。试着单步执行下面的代码,并确保您理解每行执行时会发生什么。为此,请单击此处查看交互式可视化。除了最后一行代码之外,我们以前见过所有这些语法。
1 | int[] z = null; |
最后一行演示了一种将信息从一个数组复制到另一个数组的方法。 System.arraycopy 有五个参数:
- 用作源的数组
- 在源数组中从何处开始
- 用作目标的阵列
- 在目标阵列中从何处开始
- 要复制多少项
对于Python老手来说, System.arraycopy(b, 0,x, 3, 2) 相当于Python中的 x[3:5] = b[0:2] 。
复制数组的另一种方法是使用循环。 arraycopy 通常比循环更快,并导致更紧凑的代码。唯一的缺点是 arraycopy (可以说)更难阅读。请注意,Java数组只在运行时执行边界检查。也就是说,下面的代码可以很好地编译,但是会在运行时崩溃。
1 | int[] x = {9, 10, 11, 12, 13}; |
容易数组越界
二维数组
Java中所谓的2D数组实际上只是一个数组的数组。它们遵循我们已经学习过的对象的相同规则,但是让我们回顾一下它们,以确保我们理解它们是如何工作的。
数组的数组的数组可能有点混乱。代码 int[][] bamboozle = new int[4][] 这将创建一个名为 bamboozle 的整数数组数组。具体来说,这正好创建了四个内存盒,每个内存盒都可以指向一个整数数组(长度未指定)。
尝试逐行运行下面的代码,看看结果是否符合你的直觉。如需交互式可视化,请单击此处。
1 | int[][] pascalsTriangle; |
答案:
x[0][0]: -1, w[0][0]: 1
数组 vs 类
数组和类都可以用来组织一堆内存盒。在这两种情况下,内存盒的数量是固定的,即数组的长度不能改变,就像类字段不能添加或删除一样。
数组和类中内存盒的主要区别:
- 数组框使用
[]表示法编号和访问,类框使用点表示法命名和访问。 - 数组框必须全部为同一类型。类框可以是不同的类型。
这些差异的一个特别显著的影响是, [] 表示法允许我们指定我们在运行时想要的索引。例如,考虑下面的代码:
1 | int indexOfInterest = askUserForInteger(); |
如果我们运行这段代码,我们可能会得到这样的结果:
1 | $ javac arrayDemo |
相比之下,在类中指定字段不是我们在运行时做的事情。例如,考虑下面的代码:
1 | String fieldOfInterest = "mass"; |
如果我们试着编译它,我们会得到一个语法错误。
1 | $ javac classDemo |
如果我们尝试使用点表示法,也会出现同样的问题:
1 | String fieldOfInterest = "mass"; |
编译,我们会得到:
1 | $ javac classDemo |
这并不是你经常会遇到的限制,但值得指出,只是为了获得好的奖学金。值得一提的是,有一种方法可以在运行时指定所需的字段,称为反射,但它被认为是典型程序的非常糟糕的编码风格。你可以在here阅读更多关于反射的内容。你永远不应该在任何61B程序中使用反射,我们不会在我们的课程中讨论它。
一般来说,编程语言的部分设计是为了限制程序员的选择,使代码更容易推理。通过将这些特性限制在特殊的Reflections API中,我们使典型的Java程序更易于阅读和解释。
附录:Java数组与其他语言
与其他语言中的数组相比,Java数组:
- 没有特殊的“切片”语法(比如Python)。
- 不能收缩或展开(例如在Ruby中)。
- 不要有成员方法(例如在JavaScript中)。
- 必须只包含相同类型的值(与Python不同)。
AList
在我们之前实现的DLList中,如果我们使用get()方法,与数组为基础的列表相比,它会非常的慢。这是因为,由于我们只有对列表的第一项和最后一项的引用,因此我们始终需要从前面或后面遍历列表才能找到我们尝试检索的项目。例如,如果我们想在长度为 10,000 的列表中获取项目 #417,我们必须遍历 417 个转发链接才能找到我们想要的项目。
在最坏的情况下,该项目位于最中间,我们需要浏览与列表长度成比例的多个项目(具体来说,项目数除以 2)。换言之,最坏情况下的 get 执行时间与整个列表的大小呈线性关系。这与 的 getBack 运行时形成鲜明对比,无论列表的大小如何,它都是恒定的。在本课程的后面,我们将根据大 O 和大 Theta 表示法正式定义运行时。现在,我们将坚持非正式的理解。
AList的实现(初版)
1 | /** Array based list. |
这段代码存在一个问题,如果我们创建的列表实际大小比100大,会导致越界,若我们增加一开始的item数组的大小,又会造成空间内存的浪费。
调节数组大小
方法一
1 | private void resize(int capacity) { |
从一个大小为 100 的数组开始,如果我们调用 addLast 1,000 次,大约会创建和填充500,000个内存盒
创建所有这些存储盒并重新复制其内容需要时间。在下图中,我们在顶部绘制了 SLList 的总时间与操作次数的关系,在底部绘制了基于朴素数组的列表的总时间与操作次数的关系。SLList 显示一条直线,这意味着对于每个 add 操作,列表需要相同的额外时间。这意味着每个操作都需要恒定的时间!你也可以这样想:图形是线性的,表明每个操作都需要恒定的时间,因为常数的积分是一条线。
相比之下,朴素数组列表显示抛物线,表明每个操作都需要线性时间,因为直线的积分是抛物线。这对现实世界具有重大影响。对于插入 100,000 个项目,我们可以通过计算 N^2/N 的比率来粗略计算多长时间。 将 100,000 个项目插入到我们基于数组的列表中需要 (100,000^2)/100,000 或 100,000 倍的时间。这显然是不能接受的。
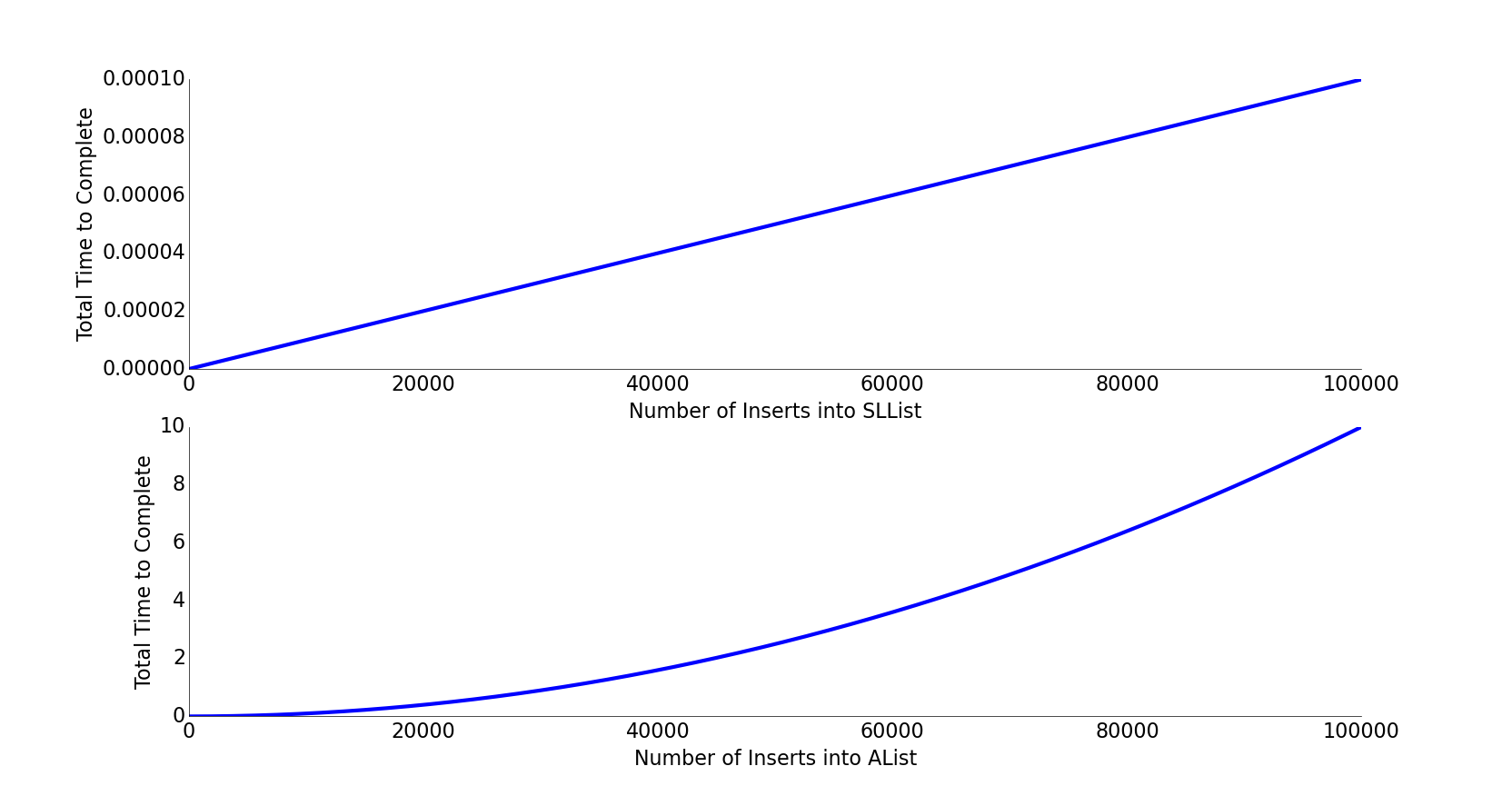
这就非常的慢了
方法二——几何大小调整
我们可以通过增加数组的大小来增加我们的性能问题,而不是增加一个加法量。也就是说,与其添加等于某个调整大小因子 RFACTOR 的内存盒数量:
1 | public void insertBack(int x) { |
相反,我们通过将框数乘以 RFACTOR 来调整大小。
1 | public void insertBack(int x) { |
重复我们之前的计算实验,我们看到我们的新 AList 插件在很短的时间内完成了 100,000 个插入,以至于我们甚至没有注意到。我们将推迟到本书的最后一章对为什么会发生这种情况进行全面分析。
内存性能
我们 AList 几乎完成了,但我们有一个主要问题。假设我们插入 1,000,000,000 个项目,然后删除 990,000,000 个项目。在这种情况下,我们将只使用 10,000,000 个内存盒,剩下 99% 完全未使用。
为了解决这个问题,我们还可以在数组开始看起来为空时缩小数组的大小。具体来说,我们定义了一个“使用比率”R,它等于列表的大小除以 items 数组的长度。例如,在下图中,使用率为0.04。
在典型的实现中,当 R 降至小于 0.25 时,我们将数组的大小减半。
泛型AList
就像我们之前所做的那样,我们可以修改我们的 AList ,以便它可以保存任何数据类型,而不仅仅是整数。为此,我们再次在类中使用特殊的角括号表示法,并在适当的情况下将任意类型参数替换为整数。例如,在下面,我们用作 Glorp 类型参数。
有一个显著的语法差异:Java 不允许我们创建泛型对象数组,因为泛型的实现方式存在一个模糊的问题。也就是说,我们不能做这样的事情:
1 | Glorp[] items = new Glorp[8]; |
相反,我们必须使用如下所示的笨拙语法:
1 | Glorp[] items = (Glorp []) new Object[8]; |
这将产生一个编译警告,但这只是我们必须忍受的事情。我们将在后面的章节中更详细地讨论这一点。
我们所做的另一个更改是,我们将“删除”的任何项目都清空。以前,我们没有理由将已删除的元素清零,而使用泛型对象,我们确实希望清空对所存储对象的引用。这是为了避免“游荡”。回想一下,Java 仅在最后一个引用丢失时销毁对象。如果我们未能清空引用,那么 Java 将不会对已添加到列表中的对象进行垃圾回收。
因为我们使用泛型对象时,相比之前的int对象,我们的列表的内存盒是指向某个对象的引用,若我们没有清空的话,该对象的内存还是会堆叠在内存中,不会被Java垃圾回收。



