CS61B学习笔记(二十)-数据结构总结
The Search Problem
我们面临的问题是:给定一个数据流,检索感兴趣的信息。
有哪些这样的例子?
- 网站用户在个人页面上发帖。仅向好友提供内容。
- 给定数千个气象站的日志,显示指定日期和时间的天气图。
- 狗主人要求最好的宠物店,选择在价格、质量或氛围方面定义他们最好的商店。
到目前为止,我们讨论的所有数据结构都是为了解决搜索问题。你可能会怎么问?我们学到的每个数据结构都用于将信息存储在方案中,从而在特定场景中提高搜索效率。
Search Data Structures 搜索数据结构
| Name | Store Operation(s) | Primary Retrieval Operation | Retrieve By |
|---|---|---|---|
| List 列表 | add(key), insert(key, index) |
get(index) |
index |
| Map | put(key, value) |
get(key) |
key identity |
| Set | add(key) |
containsKey(key) |
key identity |
| PQ | add(key) |
getSmallest() |
key order (aka key size) |
| Disjoint Sets | connect(int1, int2) |
isConnected(int1, int2) |
two integer values |
请记住,这些是抽象数据类型。这意味着我们定义行为,而不是实现。我们在前面的章节中定义了许多可能的实现。让我们考虑一下这些实现和 ADT 是如何交互的:
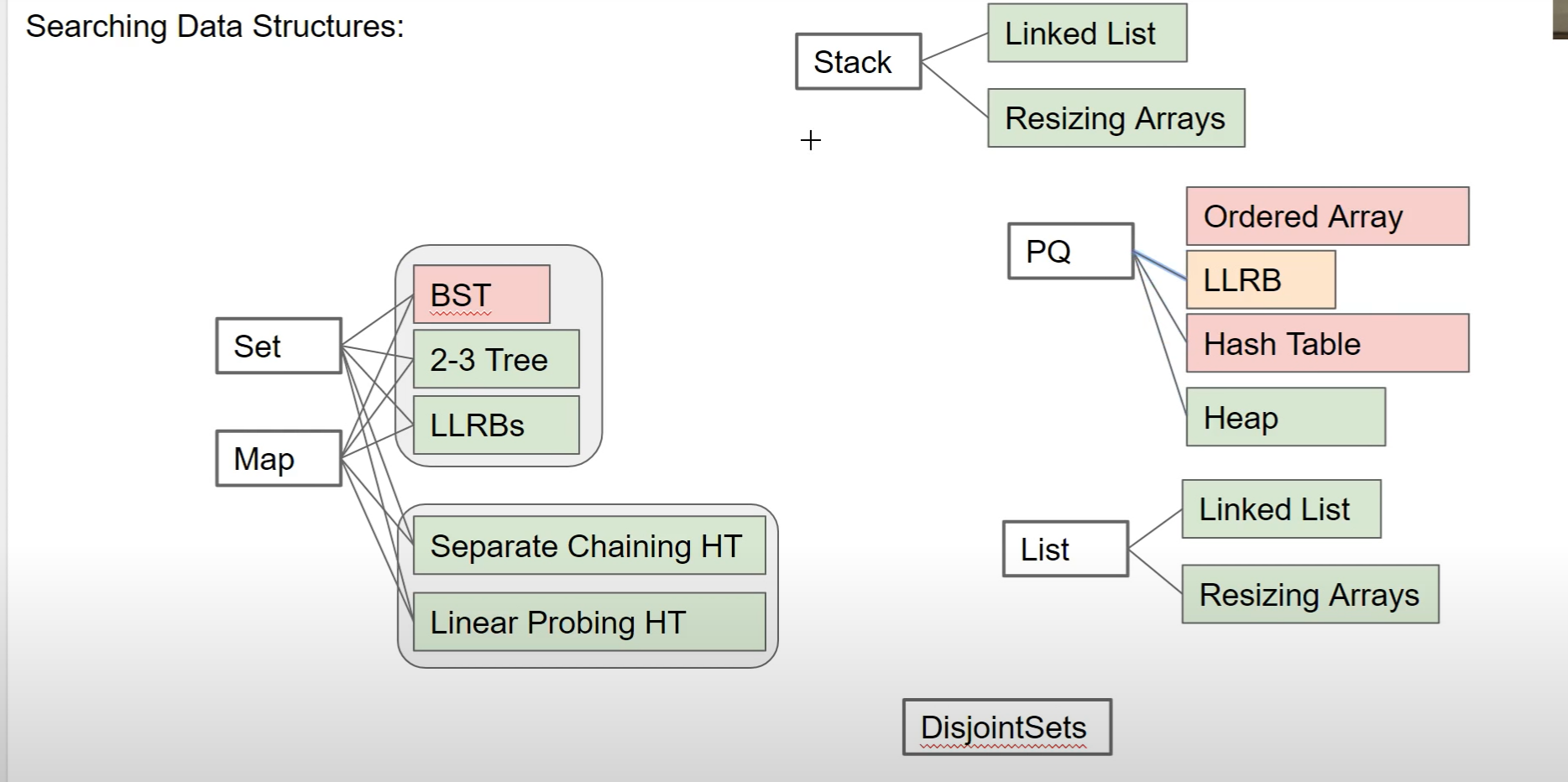
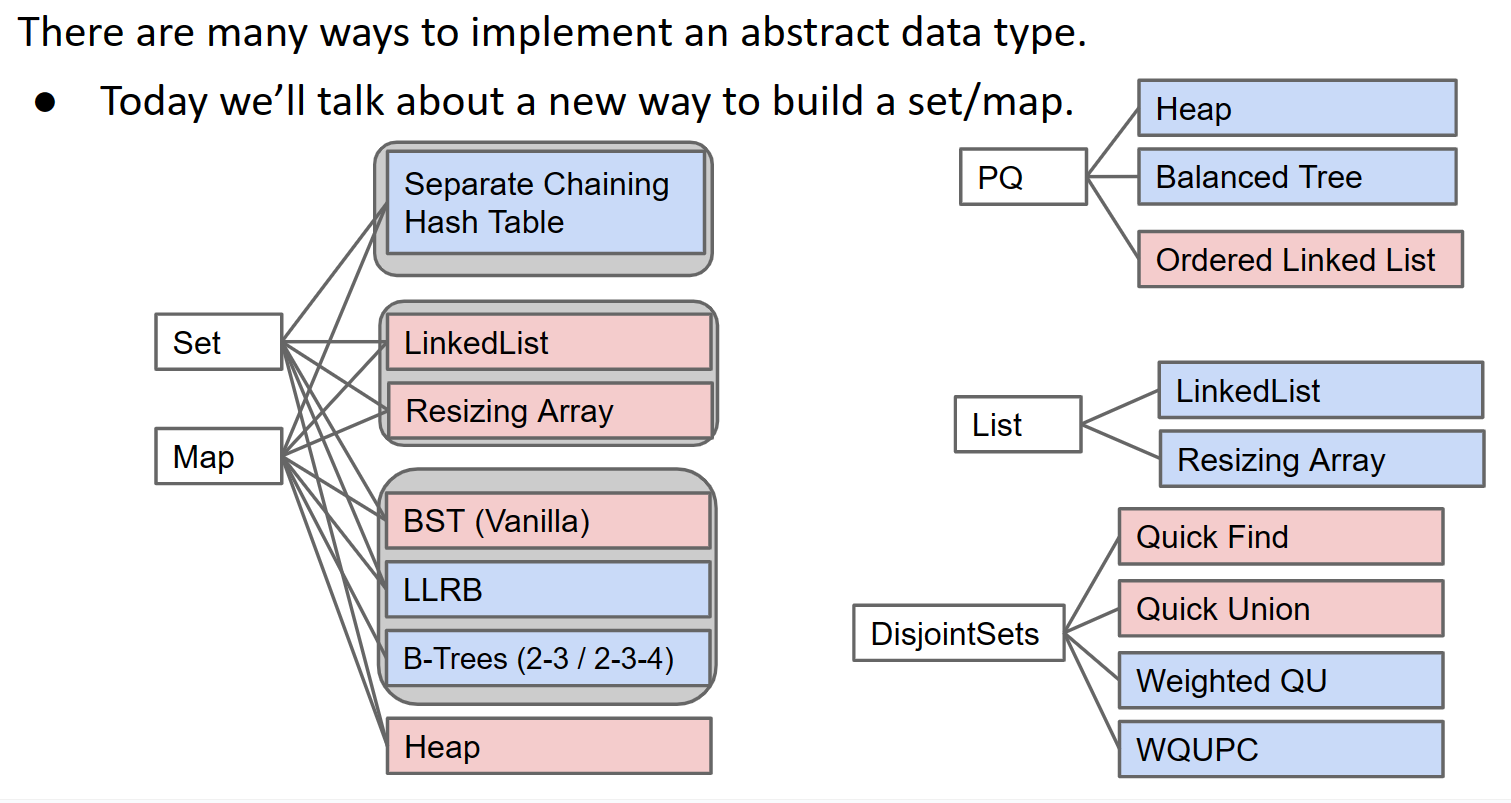
这张图告诉我们什么?您会注意到的第一件事是,我们在前面的章节中设计的许多实现可用于实现许多不同的 ADT。您还会注意到红色的实现(表示性能不佳),这告诉我们并非所有实现都最适合我们试图实现的行为。
Abstraction 抽象化
抽象通常发生在层中。抽象数据类型通常可以包含两个抽象概念,归结为一个实现。让我们考虑一些例子:
- 如果我们还记得优先级队列 ADT,我们就会试图找到一种对 PQ 操作有效的实现。我们决定使用堆有序树来实现我们的优先级队列,但正如我们所看到的,我们有几种方法(1A、1B、1C、2、3)来表示堆的树。
- 一个类似的想法是外部链接哈希表。此数据结构是使用存储桶数组实现的,但这些存储桶可以使用 ArrayList、Resizing Array、Linked List 或 BST 来完成。
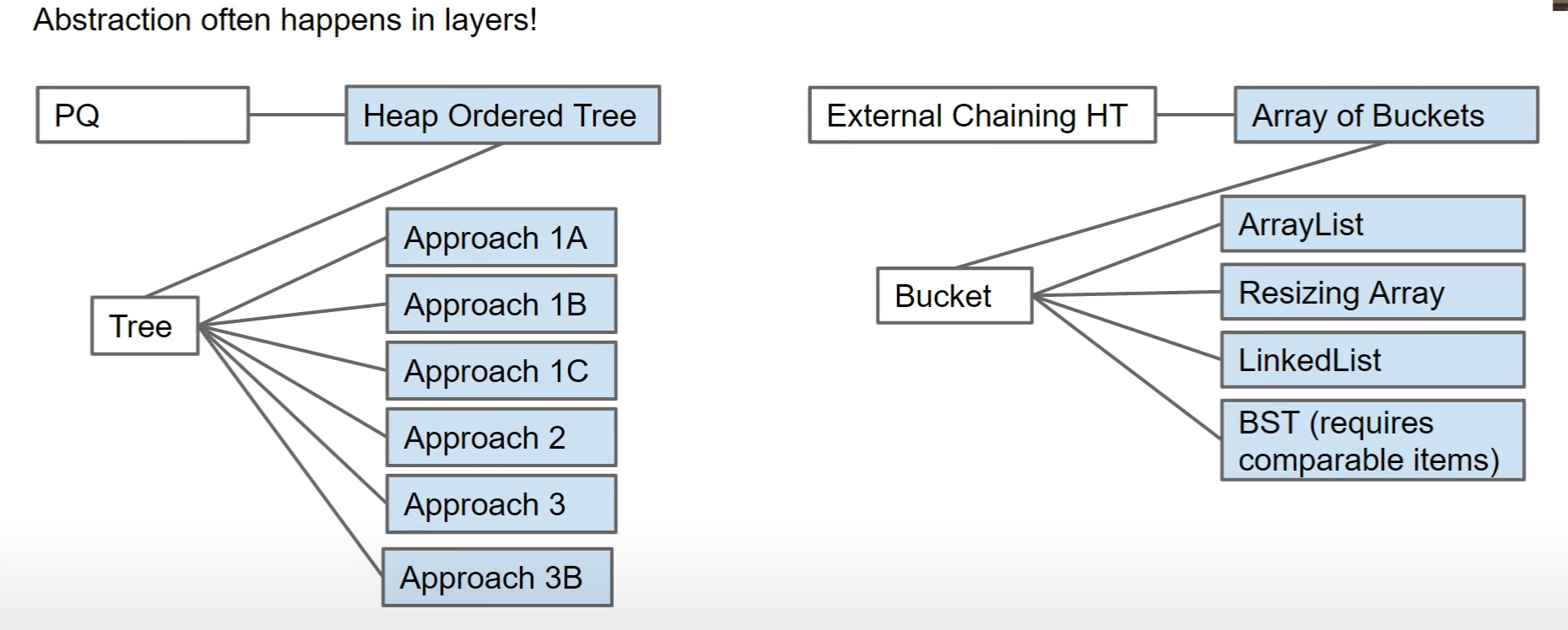
这两个例子告诉我们,我们通常可以通过使用另一个 ADT 来考虑 ADT。抽象数据类型具有抽象层,每个抽象层都定义了一个比之前的想法更具体的行为。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 云泥小窝!
相关推荐




评论